Journey to Cloud Still Too Complex
“It’s very easy as a technology provider to think that you know the right way to
do something and to tell customers that if they would just do it your way, that
everything would be easy. By the way, Oracle has definitely been guilty of this
in the past. So it’s not as though we have not made this mistake, but what is
very clear to us is that everyone wants the benefits of the cloud. Everyone’s
going there. “And the reason it’s slow is because it’s too hard. I have this
conversation differently. In the transition from when we used to have the kind
of old-school flip phones, it took about 17 seconds for everyone to have a
smartphone. Why? Because the transition was easy. It was better. “Today,
everyone knows the cloud is better, but the transition’s already taken, I don’t
know, a decade and we’re at 15% market penetration. So what that’s telling us as
a cloud provider is that we have to make it much, much easier if we’re going to
give customers those benefits quickly. “And I think when you really take that
customer first approach, and you really have that customer empathy, and you
understand why it’s difficult, that’s where you see all of these deliverables.
It’s why you see the different ways you have to build it for customers. And you
also see that around, for example, the multicloud approach.”
How to Improve Data Quality by Using Feedback Loops
If you want to tackle poor Data Quality at its source, it helps to connect those
creating the data with the people who use it, so they understand each other’s
needs and tasks better. Going back to my example above, if we could facilitate a
conversation between the sales consultant and a data analyst, I am sure the
sales consultant would better understand how important high-quality data is for
the data analyst. Similarly, the analyst could see opportunities to improve the
data collection process in customer-facing roles to help their colleague produce
much-needed data. In my work with analytics and data communities in
organizations across the world, I have seen that bringing people from different
roles together and encouraging them to learn from each other can make
significant contributions to building a data culture. For Data Quality, a
similar approach can work. Why not connect the customer-facing staff who enter
data with those who analyze it? Whether it’s the sales consultant for a mobile
phone provider, the nurse or front office staff in a hospital, or the bank
teller — each of them gathers data from customers, patients, and clients, and
the better their process is, the better the resulting Data Quality.
Batteries From Nuclear Waste That Last Thousands Of Years
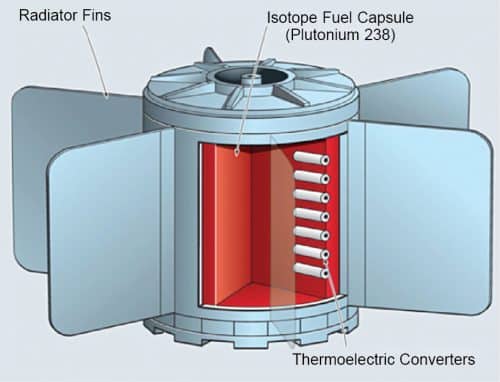
Functionally, the concept of a diamond battery is similar to that of
radioisotope electric generators used for space probes and rovers. The diamond
battery generates electric charge through direct energy conversion using a
semiconductor diode and C-14 as a radioisotope source. C-14, while undergoing
decay, emits short-range low-energy beta particles (essentially the nucleus’
version of electrons) and turns into nitrogen-14, which is not radioactive and
gets absorbed in the diamond casing. The beta particles released by C-14, moving
with an average energy of 50keV, undergo inelastic collisions with other carbon
atoms present in the diamond structure, causing electrons to jump from the
valence band to the conduction band, leaving behind holes in the valence band
where electrons were earlier present. Successive electron-hole pairs get
collected at the metal contact attached to the diamond. C-14 is preferred as the
source material because its beta particle radiation is easily absorbed by any
solid. ... The amount of C-14 used in each battery is yet to be disclosed, but
what is known is that a battery containing 1gm of C-14 would deliver 15 joules
(15J) per day, much less than an AA battery, and would take 5,730 years to reach
fifty per cent power.
When it comes to vulnerability triage, ditch CVSS and prioritize exploitability
The large number of vulnerabilities returned by automated scans is not a new
problem. In fact, it is commonly cited by developers as an obstacle to security.
To attempt to filter through these large data sets, developers conduct
vulnerability triage where they categorize the flaws that have been detected in
order of risk they pose to an application’s security or functionality. Then,
developers can fix vulnerabilities that seem to be most pressing in order to get
software out the door faster. Currently, many developers rely on the Common
Vulnerability Scoring System (CVSS). The system represents a basic standard for
assessing the severity of a vulnerability. Scores range from 0-10, with 10 being
the higher end of the scale (indicating the highest severity). Developers will
often assign CVSS scores to the vulnerabilities they detect and order them from
highest to lowest, focusing their efforts on those with the highest scores.
Unfortunately, this method is suboptimal, ultimately resulting in oversights and
less “safe” code. A large part of getting the most out of security scanning
tools comes down to a developer’s approach to triaging the vulnerabilities scans
detect.
Migrating Monoliths to Microservices With Decomposition and Incremental Changes

The problem with a distributed monolith is that it is inherently a more
distributed system, with all the associated design, runtime, and operational
challenges, yet we still have the coordination activities that a monolith
demands. I want to deploy my thing live, but I can't. I've got to wait till
you've done your change, but you can't do your change because you're waiting on
somebody else. Now, we agree: “Okay, well, on 5 July, we're all going to go
live. Is everybody ready? Three, and two, and one, and deploy.” Of course, it
always all goes fine. We never have any issues with these types of systems. If
an organization has a full-time release-coordination manager or another job
along those lines, chances are it has a distributed monolith. Coordinating
lockstep deployments of distributed systems is not fun. We end up with a much
higher cost of change. The scopes of deployments are much larger. We have more
to go wrong. We also have this inherent coordination activity, probably not only
around the release activity but also around the general deployment activity.
Even a cursory examination of lean manufacturing teaches that reducing handoffs
is key to optimizing throughput.
Why Open Source Project Maintainers are Reluctant to use Digital Signatures 2FA

Why not? Most respondents said not including 2FA was a lack of decision rather
than a decision. Many were either unaware it was an option or that because it is
not the default behavior, it was not considered, or was considered too
restrictive to require. “It wasn’t a decision, it was the default.” Some of the
detailed answers to the survey showed that security was not job number one to
many developers. They didn’t see any “need for [2FA on] low-risk projects.”
Other projects, with a handful of contributors, said they didn’t see the need at
all. And, as in the case with so many security failure rationalizations, many
thought 2FA was too difficult to use. One even said, “Adding extra hoops through
which to jump would be detrimental to the project generally. Our goal is to make
the contribution process as easy as possible.” As for digital signatures, in
which released versions come with cryptographically signed git tags (“git tag
-s”) or release packages, so that users can verify who released it even if the
distributing repo might be subverted, they’re not used anywhere near as often as
they should be either. 41.53% don’t use them at all while 35.97% use them some
of the time. A mere 22.5% use them all the time.
Machine Learning for Computer Architecture

The objective in architecture exploration is to discover a set of feasible
accelerator parameters for a set of workloads, such that a desired objective
function (e.g., the weighted average of runtime) is minimized under an optional
set of user-defined constraints. However, the manifold of architecture search
generally contains many points for which there is no feasible mapping from
software to hardware. Some of these design points are known a priori and can be
bypassed by formulating them as optimization constraints by the user (e.g., in
the case of an area budget constraint, the total memory size must not pass
over a predefined limit). However, due to the interplay of the architecture and
compiler and the complexity of the search space, some of the constraints may not
be properly formulated into the optimization, and so the compiler may not find a
feasible software mapping for the target hardware. These infeasible points are
not easy to formulate in the optimization problem, and are generally unknown
until the whole compiler pass is performed. As such, one of main challenges for
architecture exploration is to effectively sidestep the infeasible points for
efficient exploration of the search space with a minimum number of
cycle-accurate architecture simulations.
How businesses can use AI to get personalisation right

It’s not just the AI engine that is key to success. The way in which your
content is administered and managed will play a huge part. In order to quickly
serve up the right content, AI needs to be able to identify, retrieve and render
it, and having the right content structure is key to the success to this.
Content that may have traditionally lived only in the context of an authored web
page doesn’t always provide the level of granularity needed to be of any use for
personalised content. This is certainly true of product-based personalisation,
which, in turn, requires a product-based content structure to enable
personalisation engines to read individual data attributes and assemble them in
real time. Meticulous metadata is also essential to this process. Metadata is
the language that AI understands; it describes the attributes of a product such
as category, style and colour. Without the right metadata, personalisation
engines cannot identify the right content at the right time. Fast fashion
retailers, such as Asos and Boohoo, are leading the way in personalising the
presentation of products to customers in this way. Artificial intelligence is
human taught. This is the most basic thing to remember when considering an AI
implementation of any kind.
Microsoft Viva Heralds New Wave of Collaboration Tools

Viva Insights is available now in public preview. At an individual level, it is
designed to help employees protect time for regular breaks, focused work, and
learning. At a management level, leaders are able to see team trends (aggregated
and deidentified to protect privacy). The analytics offers recommendations to
better balance productivity and well-being, according to Microsoft. Viva
Learning, available now in private preview, aggregates all the learning
resources available in an organization into one place and makes them more
discoverable and accessible in the flow of work, according to Microsoft. It
incorporates content from LinkedIn Learning and Microsoft Learn as well as from
third-party providers such as Coursera and edX, plus content from each company's
own private content library. Viva Topics is now available as an add-on to
Microsoft 365 commercial plans and makes corporate knowledge easier to discover.
It uses AI to surface "topic cards" within conversations and documents across
Microsoft 365 and Teams, Microsoft said. Clicking on a card opens a topic page
with related documents, conversations, videos, and people. Microsoft Viva is not
so much new technology as it is an augmentation of Microsoft 365 and Microsoft
Teams, repackaged with some new capabilities that make existing features easier
to find and consume, according Gotta.
Building an MVP That Is Centered on User Behavior
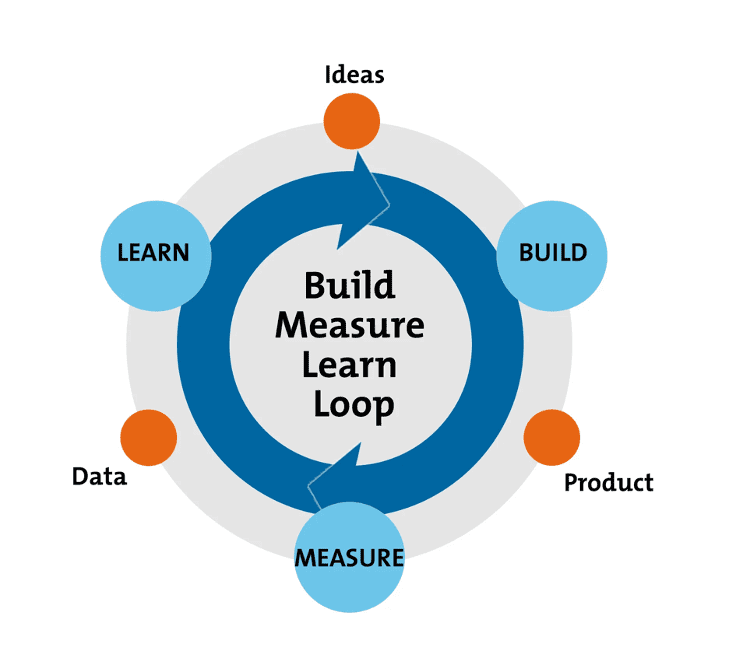
An MVP is used to test and learn from user behavior. It is used to understand
whether the product strategy is attuned to solving the user’s problems and
whether user expectations are aligned to it. To get the maximum learning from
user responses, it is necessary to highlight key differentiators that the
product is offering. The users should be able to dive straight into what is
being offered so that they can realize its true value. Also, it will help
understand whether the product will be able to withstand competition who are
offering similar or lesser alternatives. The onus is upon the ideators to
identify the key differentiators. Proper communication of the differentiators
will help the engineering team or the MVP development company to quickly build a
functional MVP. It will help accelerate the MVP loop of Build -> Measure
-> Learn. A Minimum Viable Product is like a shot at creating a first
impression on the prospects and stakeholders. It helps gauge their initial
reactions and also the need for subsequent improvisations. However, their
initial reactions cannot be read or deciphered using facial emotions or verbal
remarks. Only data can reveal how users interact and use the MVP. It will pave
the way for future construction and improvisation of the final product.
Quote for the day:
"Forget your weaknesses, increase your
strengths and be the most awesome you, that you can be." --
Tim Fargo
No comments:
Post a Comment