The definitive guide to data pipelines

A key data pipeline capability is to track data lineage, including methodologies
and tools that expose data’s life cycle and help answer questions about who,
when, where, why, and how data changes. Data pipelines transform data, which is
part of the data lineage’s scope, and tracking data changes is crucial in
regulated industries or when human safety is a consideration. ... Other data
catalog, data governance, and AI governance platforms may also have data lineage
capabilities. “Business and technical stakeholders must equally understand how
data flows, transforms, and is used across sources with end-to-end lineage for
deeper impact analysis, improved regulatory compliance, and more trusted
analytics,” says Felix Van de Maele, CEO of Collibra. The data ops behind
data pipelines When you deploy pipelines, how do you know whether they receive,
transform, and send data accurately? Are data errors captured, and do
single-record data issues halt the pipeline? Are the pipelines performing
consistently, especially under heavy load? Are transformations idempotent, or
are they streaming duplicate records when data sources have transmission errors?
Living with trust issues: The human side of zero trust architecture
As we’ve become more dependent on technology, IT environments have become more
complex. This has made threats more intense and could even pose a serious
danger. To tackle these growing security challenges — which needed a stronger
and more flexible approach — industry experts, security practitioners, and tech
providers came together to develop the zero trust architecture (ZTA) framework.
This development led to a growing recognition of the importance of prioritizing
verification over trust, which made ZTA a cornerstone of modern cybersecurity
strategies. The main idea behind ZTA is to “never trust, always
verify.” ... Implementing the ZTA framework means that every action the IT
and security teams handle is filtered through a security-first lens. However,
the over-repeated mantra of “never trust, always verify” may affect the
psychological well-being of those implementing it. Imagine spending hours
monitoring every network activity while constantly questioning if the
information is genuine and if people’s motives are pure. This suspicious climate
not only affects the work environment but also spills over into personal
interactions, affecting trust with others.
Top technologies that will disrupt business in 2025

Chaplin finds ML useful for identifying customer-related trends and predicting
outcomes. That sort of forecasting can help allocate resources more effectively,
he says, and engage customers better — for example when recommending products.
“While gen AI undoubtedly has its allure, it’s important for business leaders to
appreciate the broader and more versatile applications of traditional ML,” he
says. ... What Skillington touches on is the often-overlooked facet of any
successful digital transformation: It all starts with data. By breaking down
data silos, establishing wholistic data governance strategies, developing the
right data architecture for the business, and developing data literacy across
disciplines, organizations can not only gain better access to their data but
also better understand how ... Edge computing and 5G are two complementary
technologies that are maturing, getting smaller, and delivering tangible
business results securely, says Rogers Jeffrey Leo John, CTO and co-founder of
DataChat. “Edge devices such as mobile phones can now run intensive tasks like
AI and ML, which were once only possible in data centers,” he says.
Meta presents Transfusion: A Recipe for Training a Multi-Modal Model Over Discrete and Continuous Data
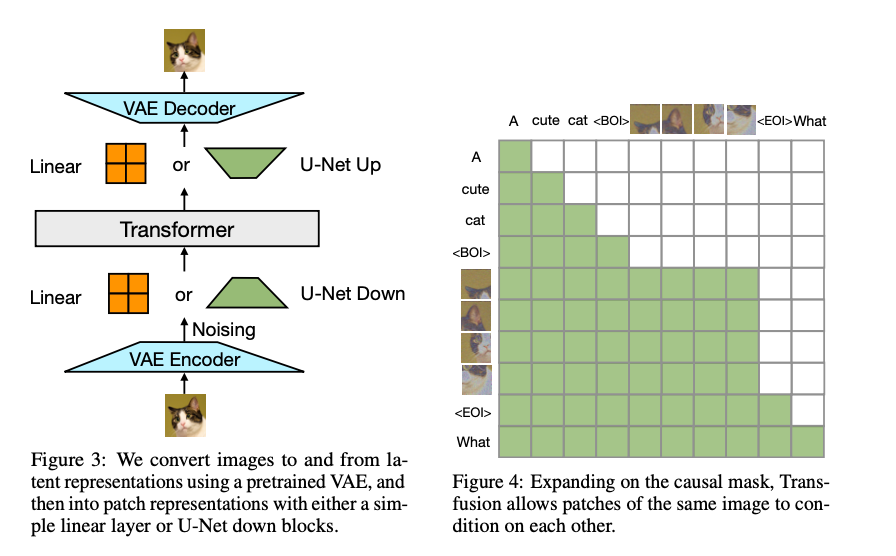
Transfusion is trained on a balanced mixture of text and image data, with each
modality being processed through its specific objective: next-token prediction
for text and diffusion for images. The model’s architecture consists of a
transformer with modality-specific components, where text is tokenized into
discrete sequences and images are encoded as latent patches using a variational
autoencoder (VAE). The model employs causal attention for text tokens and
bidirectional attention for image patches, ensuring that both modalities are
processed effectively. Training is conducted on a large-scale dataset consisting
of 2 trillion tokens, including 1 trillion text tokens and 692 million images,
each represented by a sequence of patch vectors. The use of U-Net down and up
blocks for image encoding and decoding further enhances the model’s efficiency,
particularly when compressing images into patches. Transfusion demonstrates
superior performance across several benchmarks, particularly in tasks involving
text-to-image and image-to-text generation.
AI Assistants: Picking the Right Copilot

The best assistant operates as an agent that understands what context the
underlying AI can assume from its known environment. IDE assistants such as
GitHub Copilot know that they are responding with programming projects in mind.
GitHub Copilot examines script comments as well as syntax in a given script
before crafting a suggestion. The tool examines syntax and comments against its
trained datasets, consisting of GPT training and the codebase of GitHub's public
repositories. GitHub Copilot was trained on the public repositories in GitHub,
so it has a slightly different "perspective" on syntax than that of ChatGPT ADA.
Thus, the choice of corpus for an AI model can influence what answer an AI
assistant yields to users. A good AI assistant should offer a responsive chat
feature to indicate its understanding of its environment. Jupyter, Tabnine, and
Copilot all offer a native chat UI for the user. The chat experience influences
how well a professional feels the AI assistant is working. How well it
interprets prompts and how accurate the suggestions are all start with the
conversational assistant experience, so technical professionals should note
their experiences to see which assistant works best for their projects.
Is the vulnerability disclosure process glitched? How CISOs are being left in the dark

The elephant in the room regarding misaligned motives and communications between
researchers and software vendors is that vendors frequently try to hide or
downplay the bugs that researchers feel obligated to make public. “The root
cause is a deep-seated fear and prioritizing reputation over security of users
and customers,” Rapid7’s Condon says. “What it comes down to many times is that
organizations are afraid to publish vulnerability information because of what it
might mean for them legally, reputationally, and financially if their customers
leave. Without a concerted effort to normalize vulnerability disclosure to
reward and incentivize well-coordinated vulnerability disclosure, we can pick at
communication all we want. Still, the root cause is this fear and the conflict
that it engenders between researchers and vendors.” Condon is, however,
sympathetic to the vendors’ fears. “They don’t want any information out there
because they are understandably concerned about reputational damage. They’re
seeing major cyberattacks in the news, CISOs and CEOs dragged in front of
Congress or the Senate here in the US, and lawsuits are coming out against them.
...”
Level Up Your Software Quality With Static Code Analysis

Behind high-quality software is high-quality code. The same core coding
principles remain true regardless of how the code was written, either by
humans or AI coding assistants. Code must be easy to read, maintain,
understand and change. Code structure and consistency should be robust and
secure to ensure the application performs well. Code devoid of issues helps
you attain the most value from your software. ... While static analysis
focuses on code quality and reduces the number of problems to be found later
in the testing stage, application testing ensures that your software actually
runs as it was designed. By incorporating both automated testing and static
analysis, developers can manage code quality through every stage of the
development process, quickly find and fix issues and improve the overall
reliability of their software. A combination of both is vital to software
development. In fact, a good static analysis tool can even be integrated into
your testing tools to track and report the percentage of code covered by your
unit tests. Sonar recommends a test code coverage of 80% or your code will
fail to pass the recommended standard.
Two strategies to protect your business from the next large-scale tech failure
The key to mitigating another large-scale system failure is to plan for
catastrophic events and practice your response. Make dealing with failure part
of normal business practices. When failure is unexpected and rare, the
processes to deal with it are untested and may even result in actions which
make the failure worse. Build a network and a team that can adapt and react to
failures. Remember when insurance companies ran their own data centres and
disaster recovery tests were conducted twice a year? ... The second strategy
for minimizing large-scale failures is to avoid the software monoculture
created by the concentration of digital tech suppliers. It’s more complex but
worth it. Some corporations have a policy of buying their core networking
equipment from three or four different vendors. Yes, it makes day-to-day
management a little more difficult, but they have the assurance that if one
vendor has a failure, their entire network is not toast. Whether it’s tech or
biology, a monoculture is extremely vulnerable to epidemics which can destroy
the entire system. In the CrowdStrike scenario, if corporate networks had been
a mix of Windows, Linux and other operating systems, the damage would not have
been as widespread.
India's Critical Infrastructure Suffers Spike in Cyberattacks

The adoption of emerging technologies such as AI and cloud and the focus on
innovation and remote working has driven digital transformations, thus
boosting companies' need for more security defenses, according to Manu
Dwivedi, partner and leader for cybersecurity at consultancy PwC India.
"AI-enabled phishing and aggressive social engineering have elevated
ransomware to the top concern," he says. "While cloud-related threats are
concerning, greater interconnectivity between IT and OT environments and
increased usage of open-source components in software are increasing the
available threat surface for attackers to exploit." Indian organizations also
need to harden their systems against insider threats, which requires a
combination of business strategy, culture, training, and governance processes,
Dwivedi says. ... The growing demand for AI has also shaped the threat
landscape in the country and threat actors have already started experimenting
with different AI models and techniques, says PwC India's Dwivedi. "Threat
actors are expected to use AI to generate customized and polymorphic malware
based on system exploits, which escapes detection from signature-based and
traditional detection methods," he says.
Architectural Patterns for Enterprise Generative AI Apps
In the RAG pattern, we integrate a vector database that can store and index
embeddings (numerical representations of digital content). We use various
search algorithms like HNSW or IVF to retrieve the top k results, which are
then used as the input context. The search is performed by converting the
user's query into embeddings. The top k results are added to a
well-constructed prompt, which guides the LLM on what to generate and the
steps it should follow, as well as what context or data it should consider.
... GraphRAG is an advanced RAG approach that uses a graph database to
retrieve information for specific tasks. Unlike traditional relational
databases that store structured data in tables with rows and columns, graph
databases use nodes, edges, and properties to represent and store data. This
method provides a more intuitive and efficient way to model, view, and query
complex systems. ... Like the basic RAG system, GraphRAG also uses a
specialized database to store the knowledge data it generates with the help of
an LLM. However, generating the knowledge graph is more costly compared to
generating embeddings and storing them in a vector database.
Quote for the day:
"Leadership is a matter of having
people look at you and gain confidence, seeing how you react. If you're in
control, they're in control." -- Tom Landry
No comments:
Post a Comment