The Increasingly Graphic Nature Of Intel Datacenter Compute
What customers are no doubt telling Intel and AMD is that they want highly tuned
pieces of hardware co-designed with very precise workloads, and that they will
want them at much lower volumes for each multi-motor configuration than chip
makers and system builders are used to. Therefore, these compute engine
complexes we call servers will carry higher unit costs than chip makers and
system builders are used to, but not necessarily with higher profits. In fact,
quite possibly with lower profits, if you can believe it. This is why Intel is
taking a third whack at discrete GPUs with its Xe architecture and significantly
with the “Ponte Vecchio” Xe HPC GPU accelerator that is at the “Aurora”
supercomputer at Argonne National Laboratory. And this time the architecture of
the GPUs is a superset of the integrated GPUs for its laptops and desktops, not
some Frankenstein X86 architecture that is not really tuned for graphics even if
it could be used as a massively parallel compute engine in a way that GPUs have
been transformed from Nvidia and AMD.
Under the hood: Meta’s cloud gaming infrastructure
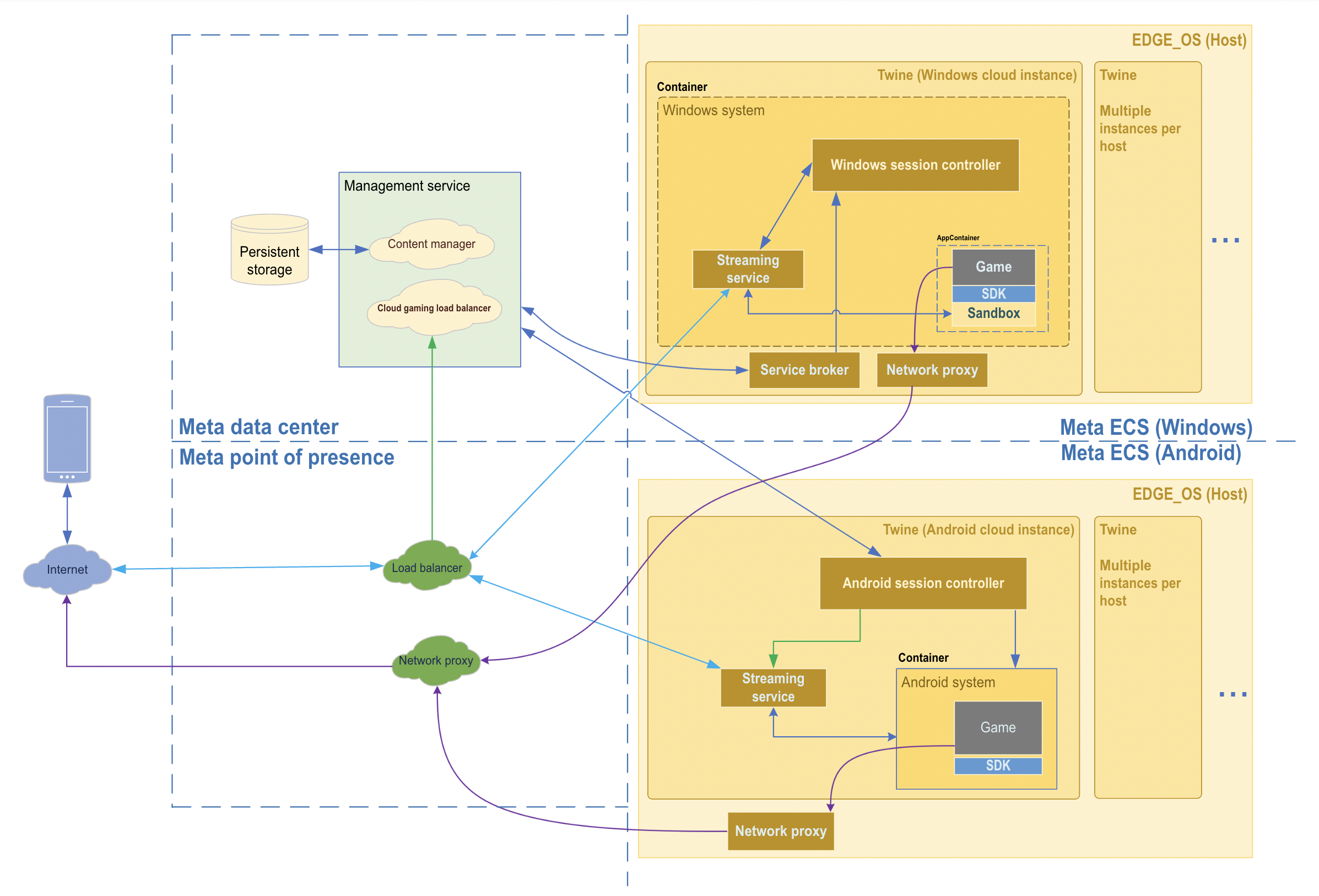
Our goal within each edge computing site is to have a unified hosting
environment to make sure we can run as many games as possible as smoothly as
possible. Today’s games are designed for GPUs, so we partnered with NVIDIA to
build a hosting environment on top of NVIDIA Ampere architecture-based GPUs. As
games continue to become more graphically intensive and complex, GPUs will
provide us with the high fidelity and low latency we need for loading, running,
and streaming games. To run games themselves, we use Twine, our cluster
management system, on top of our edge computing operating system. We build
orchestration services to manage the streaming signals and use Twine to
coordinate the game servers on edge. We built and used container technologies
for both Windows and Android games. We have different hosting solutions for
Windows and Android games, and the Windows hosting solution comes with the
integration with PlayGiga. We’ve built a consolidated orchestration system to
manage and run the games for both operating systems.
Google AI Introduces ‘LIMoE’

A typical Transformer comprises several “blocks,” each containing several
distinct layers. A feed-forward network is one of these layers (FFN). This
single FFN is replaced in LIMoE and the works described above by an expert layer
with multiple parallel FFNs, each of which is an expert. A primary router
predicts which experts should handle which tokens, given a series of passes to
process. ... The model’s price is comparable to the regular Transformer model if
only one expert is activated. LIMoE performs exactly that, activating one expert
per case and matching the dense baselines’ computing cost. The LIMoE router, on
the other hand, may see either image or text data tokens. When MoE models try to
deliver all tokens to the same expert, they fail uniquely. Auxiliary losses, or
additional training objectives, are commonly used to encourage balanced expert
utilization. Google AI team discovered that dealing with numerous modalities
combined with sparsity resulted in novel failure modes that conventional
auxiliary losses could not solve. To address this, they created additional
losses.
Stop Splitting Yourself in Half: Seek Out Work-Life Boundaries, Not Balance
What makes boundaries different from balance? Balance implies two things that
aren't equal that you're constantly trying to make equal. It creates the
expectation of a clear-cut division. A work-life balance fails to acknowledge
that you are a whole person, and sometimes things can be out of balance
without anything being wrong. Sometimes you'll spend days, weeks and even
whole seasons of life choosing to lean more into one part of your life than
the other. Boundaries ask you to think about what's important to you, what
drives you, and what authenticity looks like for you. Boundaries require
self-awareness and self-reflection, along with a willingness and ability to
prioritize. Those qualities help you to be more aware and more capable of
making decisions at a given moment. By establishing boundaries grounded in
your priorities, you're more equipped to make choices. Boundaries empower you
to say, "This is what I'm choosing right now. I need to be fully here until
this is done." Boundaries aren't static, either.
Why it’s time for 'data-centric artificial intelligence'

AI systems need both code and data, and “all that progress in algorithms means
it's actually time to spend more time on the data,” Ng said at the recent
EmTech Digital conference hosted by MIT Technology Review. Focusing on
high-quality data that is consistently labeled would unlock the value of AI
for sectors such as health care, government technology, and manufacturing, Ng
said. “If I go see a health care system or manufacturing organization,
frankly, I don't see widespread AI adoption anywhere.” This is due in part to
the ad hoc way data has been engineered, which often relies on the luck or
skills of individual data scientists, said Ng, who is also the founder and CEO
of Landing AI. Data-centric AI is a new idea that is still being discussed, Ng
said, including at a data-centric AI workshop he convened last December. ...
Data-centric AI is a key part of the solution, Ng said, as it could provide
people with the tools they need to engineer data and build a custom AI system
that they need. “That seems to me, the only recipe I'm aware of, that could
unlock a lot of this value of AI in other industries,” he said.
How Do We Utilize Chaos Engineering to Become Better Cloud-Native Engineers?
The main goal of Chaos Engineering is as explained here: “Chaos Engineering is
the discipline of experimenting on a system in order to build confidence in the
system’s capability to withstand turbulent conditions in production.” The idea
of Chaos Engineering is to identify weaknesses and reduce uncertainty when
building a distributed system. As I already mentioned above, building
distributed systems at scale is challenging, and since such systems tend to be
composed of many moving parts, leveraging Chaos Engineering practices to reduce
the blast radius of such failures, proved itself as a great method for that
purpose. We leverage Chaos Engineering principles to achieve other things
besides its main objective. The “On-call like a king” workshops intend to
achieve two goals in parallel—(1) train engineers on production failures that we
had recently; (2) train engineers on cloud-native practices, tooling, and how to
become better cloud-native engineers!
The 3 Phases of Infrastructure Automation

Manually provisioning and updating infrastructure multiple times a day from
different sources, in various clouds or on-premises data centers, using
numerous workflows is a recipe for chaos. Teams will have difficulty
collaborating or even sharing a view of the organization’s infrastructure. To
solve this problem, organizations must adopt an infrastructure provisioning
workflow that stays consistent for any cloud, service or private data center.
The workflow also needs extensibility via APIs to connect to infrastructure
and developer tools within that workflow, and the visibility to view and
search infrastructure across multiple providers. ... The old-school,
ticket-based approach to infrastructure provisioning makes IT into a
gatekeeper, where they act as governors of the infrastructure but also create
bottlenecks and limit developer productivity. But allowing anyone to provision
infrastructure without checks or tracking can leave the organization
vulnerable to security risks, non-compliance and expensive operational
inefficiencies.
Questioning the ethics of computer chips that use lab-grown human neurons

While silicon computers transformed society, they are still outmatched by
the brains of most animals. For example, a cat’s brain contains 1,000 times
more data storage than an average iPad and can use this information a
million times faster. The human brain, with its trillion neural connections,
is capable of making 15 quintillion operations per second. This can only be
matched today by massive supercomputers using vast amounts of energy. The
human brain only uses about 20 watts of energy, or about the same as it
takes to power a lightbulb. It would take 34 coal-powered plants generating
500 megawatts per hour to store the same amount of data contained in one
human brain in modern data storage centres. Companies do not need brain
tissue samples from donors, but can simply grow the neurons they need in the
lab from ordinary skin cells using stem cell technologies. Scientists can
engineer cells from blood samples or skin biopsies into a type of stem cell
that can then become any cell type in the human body.
How Digital Twins & Data Analytics Power Sustainability

Seeding technology innovation across an enterprise requires broader and
deeper communication and collaboration than in the past, says Aapo
Markkanen, an analyst in the technology and service providers research unit
at Gartner. “There’s a need to innovate and iterate faster, and in a more
dynamic way. Technology must enable processes such as improved materials
science and informatics and simulations.” Digital twins are typically at the
center of the equation, says Mark Borao, a partner at PwC. Various groups,
such as R&D and operations, must have systems in place that allow teams
to analyze diverse raw materials, manufacturing processes, and recycling and
disposal options --and understand how different factors are likely to play
out over time -- and before an organization “commits time, money and other
resources to a project,” he says. These systems “bring together data and
intelligence at a massive scale to create virtual mirrored worlds of
products and processes,” Podder adds. In fact, they deliver visibility
beyond Scope 1 and Scope 2 emissions, and into Scope 3 emissions.
API security warrants its own specific solution
If the API doesn’t apply sufficient internal rate limiting on parameters
such as response timeouts, memory, payload size, number of processes,
records and requests, attackers can send multiple API requests creating a
denial of service (DoS) attack. This then overwhelms back-end systems,
crashing the application or driving resource costs up. Prevention requires
API resource consumption limits to be set. This means setting thresholds for
the number of API calls and client notifications such as resets and
lockouts. Server-side, validate the size of the response in terms of the
number of records and resource consumption tolerances. Finally, define and
enforce the maximum size of data the API will support on all incoming
parameters and payloads using metrics such as the length of strings and
number of array elements. Effectively a different spin on BOLA, this sees
the attacker able to send requests to functions that they are not permitted
to access. It’s effectively an escalation of privilege because access
permissions are not enforced or segregated, enabling the attacker to
impersonate admin, helpdesk, or a superuser and to carry out commands or
access sensitive functions, paving the way for data exfiltration.
Quote for the day:
"To make a decision, all you need is
authority. To make a good decision, you also need knowledge, experience,
and insight." -- Denise Moreland
No comments:
Post a Comment