Zero-Trust For All: A Practical Guide

In general, zero-trust initiatives have two goals in mind: reduce the attack
surface and increase visibility. To demonstrate this, consider the (common)
scenario of a ransomware gang buying initial access to a company’s cloud through
an underground initial-access broker and then attempting to mount an attack. In
terms of visibility, “zero trust should stop that attack, or make it so
difficult that it will be spotted much earlier,” said Greg Young, vice president
of cybersecurity at Trend Micro. “If companies know the postures of their
identities, applications, cloud workloads, data sources and containers involved
in the cloud, it should make it exceedingly hard for attackers. Knowing what is
unpatched, what is an untrusted lateral movement, and continuously monitoring
the posture of identities really limits the attack surface available to them.”
And on the attack-surface front, Malik noted that if the gang used a zero-day or
unpatched vulnerability to gain access, zero trust will box the attackers in.
“First, at some point the attackers will cause a trusted user or process to
begin misbehaving,” he explained.
Web3 Security: Attack Types and Lessons Learned
Expert adversaries, often called Advanced Persistent Threats (APTs), are the
boogeymen of security. Their motivations and capabilities vary widely, but they
tend to be well-heeled and, as the moniker suggests, persistent; unfortunately,
it’s likely they will always be around. Different APTs run many different types
of operations, but these threat actors tend to be the likeliest to attack the
network layer of companies directly to accomplish their goals. We know some
advanced groups are actively targeting web3 projects, and we suspect there are
others who have yet to be identified. ... One of the most well-known APTs is
Lazarus, a North Korean group which the FBI recently attributed as having
conducted the largest crypto hack to date. ... Now that web3 lets people
directly trade assets, such as tokens or NFTs, with almost instant finality,
phishing campaigns are targeting its users. These attacks are the easiest way
for people with little knowledge or technical expertise to make money stealing
crypto. Even so, they remain a valuable method for organized groups to go after
high-value targets, or for advanced groups to wage broad-based, wallet-draining
attacks through, for example, website takeovers.
The New Face of Data Governance

In light of the changes in the nature of data, the level of data regulation, and
the data democratization trend, it’s safe to say that the traditional, old,
boring, data governance is dead. We can’t let it in the grave, as we need data
governance more than ever today. Our job is thus to resurrect it, and give it a
new face. ... Data governance should embrace the trends of operational analytics
and data democratization, and ensure that anybody can use data at any time to
make decisions with no barrier to access or understanding. Data democratization
means that there are no gatekeepers creating a bottleneck at the gateway to
data. This is worth mentioning, as the need for data governance to be secure and
compliant often leads programs to create bottlenecks at the gateway to data, as
the IT team is usually put in charge of granting access to data. Operational
people can end up waiting hours until they manage to get access to a dataset. By
then, they have already given up on their analysis. It’s important to have
security and control, but not at the expense of the agility that data offers.
It’s time for businesses to embrace the immersive metaverse

Companies need to understand what’s possible in the metaverse, what’s already in
use and what customers or employees will expect as more organizations create
immersive experiences to differentiate their products and services. The
possibilities may include improvements in what companies are doing now as well
as revolutionary changes in the way companies operate, connect and engage with
customers and employees to increase loyalty. How can leaders start to identify
opportunities in the metaverse? Start, as always, with low-hanging fruit, like
commerce and brand experiences that can benefit from immersive support. Also
consider the technology that can enable what you need. From an architectural
standpoint, it’s helpful to think of immersive experiences as a three-layer
cake. The top layer is where users get access via systems of engagement. The
middle layer is where messages are sent, received and routed to the right people
via systems of integration. The bottom layer comprises the databases and
transactions — the systems of record.
Why it’s so damn hard to make AI fair and unbiased
:format(webp)/cdn.vox-cdn.com/uploads/chorus_image/image/70765625/ai_bias_board_1.0.jpg)
The problem is that if there’s a predictable difference between two groups on
average, then these two definitions will be at odds. If you design your search
engine to make statistically unbiased predictions about the gender breakdown
among CEOs, then it will necessarily be biased in the second sense of the word.
And if you design it not to have its predictions correlate with gender, it will
necessarily be biased in the statistical sense. So, what should you do? How
would you resolve the trade-off? Hold this question in your mind, because we’ll
come back to it later. While you’re chewing on that, consider the fact that just
as there’s no one definition of bias, there is no one definition of fairness.
Fairness can have many different meanings — at least 21 different ones, by one
computer scientist’s count — and those meanings are sometimes in tension with
each other. “We’re currently in a crisis period, where we lack the ethical
capacity to solve this problem,” said John Basl, a Northeastern University
philosopher who specializes in emerging technologies. So what do big players in
the tech space mean, really, when they say they care about making AI that’s fair
and unbiased?
Quantum computing to run economic models on crypto adoption

Indeed, QC makes use of an uncanny quality of quantum mechanics whereby an
electron or atomic particle can be in two states at the same time. In classical
computing, an electric charge represents information as either an 0 or a 1 and
that is fixed, but in quantum computing, an atomic particle can be both a 0 and
a 1, or a 1 and a 1, or a 0 and a 0, etc. If this unique quality can be
harnessed, computing power explodes manyfold, and QC’s development, paired with
Shor’s algorithm — first described in 1994 as a theoretical possibility, but
soon to be a wide-reaching reality, many believe — also threatens to burst apart
RSA encryption, which is used in much of the internet including websites and
email. “Yes, it’s a very tough and exciting weapons race,” Miyano told
Cointelegraph. “Attacks — including side-channel attacks — to cryptosystems are
becoming more and more powerful, owing to the progress in computers and
mathematical algorithms running on the machines. Any cryptosystem could be
broken suddenly because of the emergence of an incredibly powerful
algorithm.”
Cybercriminals are finding new ways to target cloud environments

Criminals have also shifted their focus from Docker to Kubernetes. Attacks
against vulnerable Kubernetes deployments and applications increased to 19% in
2021, up from 9% in 2020. Kubernetes environments are a tempting target, as once
an attacker gains initial access, they can easily move laterally to expand their
presence. Attacks that affect an entire supply chain have increased over the
past few years, and that has been felt across the software supply chain as well.
In 2021, attackers aiming at software suppliers as well as their customers and
partners employed a variety of tactics, including exploiting open source
vulnerabilities, infecting popular open source packages, compromising CI/CD
tools and code integrity, and manipulating the build process. Last year,
supply-chain attacks accounted for 14.3% of the samples seen from public image
libraries. “These findings underscore the reality that cloud native environments
now represent a target for attackers, and that the techniques are always
evolving,” said Assaf Morag, threat intelligence and data analyst lead for
Aqua’s Team Nautilus.
Addressing the last mile problem with MySQL high availability
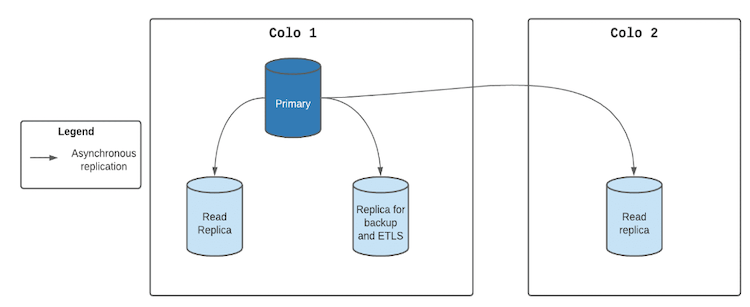
Because a single database server is shared between a variety of client
applications, a single rogue transaction from an unoptimized query could
potentially modify millions of rows in one of the databases on the server,
causing performance implications for the other databases. These transactions
have the potential to overload the I/O subsystem and stall the database server.
In this situation, the Orchestrator is unable to get a response from the primary
node, and the replicas also face issues in connecting to the primary. This
causes the Orchestrator to initiate a failover. This problem is compounded by
the application re-trying these transactions upon failure, and stalling the
database operations repeatedly. These transactions halt the database for many
seconds and the Orchestrator is quick to catch the stalled state and initiate a
failover, impacting the general availability of the MySQL platform. We knew that
MySQL stores the number of rows modified by any running transaction, and this
number can be obtained by querying the trx_rows_modified of the innodb_trx
table, in the information_schema database.
California eyes law to protect workers from digital surveillance

The bill would “establish much needed, yet reasonable, limitations on how
employers use data-driven technology at work,” Kalra told the Assembly Labor and
Employment Committee on Wednesday. “The time is now to address the increasing
use of unregulated data-driven technologies in the workplace and give workers —
and the state — the necessary tools to mitigate any insidious impacts caused by
them.” The use of digital surveillance software grew during the
pandemic as employers sought to track employees’ productivity and activity when
working from home, installing software that uses techniques such as keystroke
logging and webcam monitoring. Digital monitoring and management is being used
across a variety sectors, with warehouse staff, truck drivers and ride-hailing
drivers subject to movement and location tracking for example, with decisions
around promotions, hiring and even firing made by algorithms in some cases. The
bill, which was approved by the committee on a 5-2 vote and now moves to the
Appropriations Committee for more debate, makes three core proposals
Data privacy: 5 mistakes you are probably making

It is a mistake to act on laws that apply only in the geographic location of
business operations. There might be privacy regulations/compliance issues that
apply to a company beyond those that exist where the company is located – for
example, a company headquartered in New York might have customers in Europe, and
some European data privacy regulations likely would apply beyond any U.S.-based
regulations. This is a significant problem with breach response laws. A large
number of U.S. organizations follow the requirements only for their own state or
territory. There are at least 54 U.S. state/territory breach laws, so this
belief could be very costly. Privacy management programs should apply to all
applicable laws and regulations of the associated individuals and also
synthesize all requirements so that one set of procedures can be followed to
address the common requirements, in addition to meeting unique requirements for
specific laws. Many organizations are also overconfident that they will not
experience a privacy breach, which leaves them unable to respond effectively,
efficiently, and fully when a breach does happen.
Quote for the day:
"Leadership is just another word for
training." -- Lance Secretan
No comments:
Post a Comment