Deep Dive into CQRS — A Great Microservices Pattern
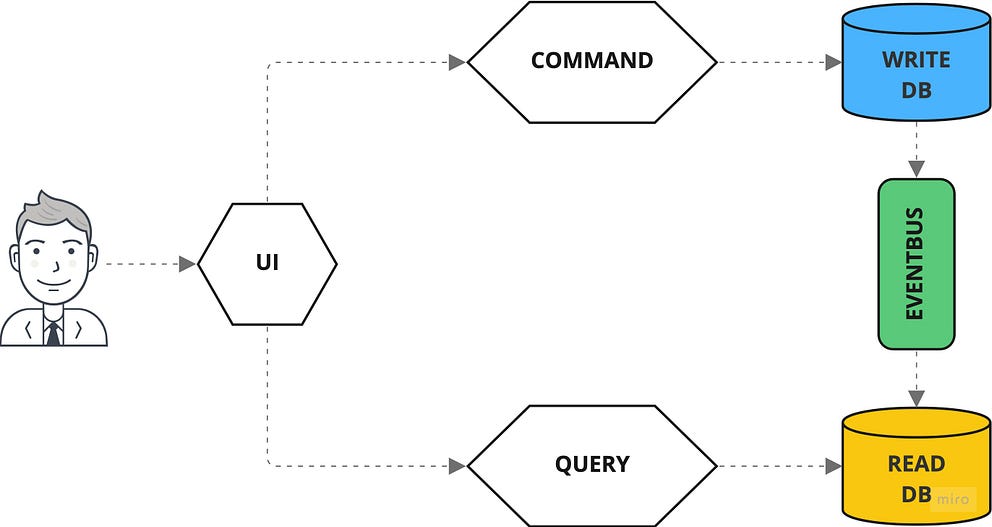
If you want to implement the CQRS pattern into an API, it is not enough to
separate the routes via POST and GET. You also have to think about how you can
ensure that command doesn’t return anything or at least nothing but metadata.
The situation is similar to the Query API. Here, the URL path describes the
desired query, but in this case, the parameters are transmitted using the query
string since it is a GET request. Since the queries access the read-optimized
denormalized database, the queries can be executed quickly and efficiently.
However, the problem is that without regularly pulling the query routes, a
client does not find out whether a command has already been processed and what
the result was. Therefore, it is recommended to use a third API, the Events API,
which informs about events via push notifications via web sockets, HTTP
streaming, or a similar mechanism. Anyone who knows GraphQL and is reminded of
the concepts of mutation, query, and subscription when describing the commands,
the query, and the events API is on the right track: GraphQL is ideal for
implementing CQRS-based APIs.
Why hybrid intelligence is the future of artificial intelligence at McKinsey

“One thing that hasn’t changed: our original principle of combining the
brilliance of the human mind and domain expertise with innovative technology to
solve the most difficult problems,” explains Alex Sukharevsky. “We call it
hybrid intelligence, and it starts from day one on every project.” AI
initiatives are known to be challenging; only one in ten pilots moves into
production with significant results. “Adoption and scaling aren’t things you add
at the tail end of a project; they’re where you need to start,” points out Alex
Singla. “We bring our technical leaders together with industry and
subject-matter experts so they are part of one process, co-creating solutions
and iterating models. They come to the table with the day-to-day insights of
running the business that you’ll never just pick up from the data alone.” Our
end-to-end and transformative approach is what sets McKinsey apart. Clients are
taking notice: two years ago, most of our AI work was single use cases, and now
roughly half is transformational. Another differentiating factor is the assets
created by QuantumBlack Labs.
Top 10 FWaaS providers of 2022

As cloud solutions continued to evolve, cloud-based security services had to
follow their lead and this is how firewall as a service (FWaaS) came into
existence. In short, FWaaS took the last stage of firewall evolution - the
next-generation firewall (NGFW) - and moved it from a physical device to the
cloud. There are plenty of benefits of employing FWaaS in your systems in place
of an old-fashioned firewall and some of them are simplicity, superior
scalability, improved visibility and control, protection of remote workers, and
cost-effectiveness. ... Unlike old-fashioned firewalls, Perimeter 81’s solution
can safeguard multiple networks and control access to all data and resources of
an organization. Some of its core features include identity-based access, global
gateways, precise network segmentation, object-based configuration management,
multi-site management, protected DNS system, safe remote work, a wide variety of
integrations, flexible features, and scalable pricing. ... Secucloud’s FWaaS is
a zero-trust, next-gen, AI-based solution that utilizes threat intelligence
feed, secures traffic through its own VPN tunnel, and operates as a proxy
providing an additional layer of security to your infrastructure.
Automated Security Alert Remediation: A Closer Look

To properly implement automatic security alert remediation, you must choose the
remediation workflow that works best for your organization. Alert management
works with workflows that are scripted to match a certain rule to identify
possible vulnerabilities and execute resolution tasks. With automation,
workflows are automatically triggered by following asset rules and constantly
inspecting the remediation activity logs to execute remediation. To improve mean
time to response and remediation, organizations create automated remediation
workflows. For example, remediation alert playbooks aid in investigating events,
blocking IP addresses or adding an IOC on a cloud firewall. There are also
interactive playbooks that can help remediate issues like a DLP incident on a
SaaS platform while also educating the user via dynamic interactions using the
company’s communication tools. The typical alert remediation workflow consists
of multiple steps. It begins with the creation of a new asset policy followed by
the selection of a remediation action rule and concludes with the continued
observation of the automatically quarantined rules.
Experts outline keys for strong data governance framework

It's needed to manage risk, which could be anything from the use of low-quality
data that leads to a bad decision to potentially running afoul of regulatory
restrictions. And it's also needed to foster informed decisions that lead to
growth. But setting limits on which employees can use what data, while further
limiting how certain employees can use data depending on their roles, and
simultaneously encouraging those same employees to explore and innovate with
data are seemingly opposing principles. So a good data governance framework
finds an equilibrium between risk management and enablement, according to Sean
Hewitt, president and CEO of Succeed Data Governance Services, who spoke during
a virtual event on April 26 hosted by Eckerson Group on data governance. A good
data governance framework instills confidence in employees that whatever data
exploration and decision-making they do in their roles, they're doing so with
proper governance guardrails in place so they're exploring and making decisions
safely and securely and won't hurt their organization.
Augmented data management: Data fabric versus data mesh

The data fabric architectural approach can simplify data access in an
organization and facilitate self-service data consumption at scale. This
approach breaks down data silos, allowing for new opportunities to shape data
governance, data integration, single customer views and trustworthy AI
implementations among other common industry use cases. Since its uniquely
metadata-driven, the abstraction layer of a data fabric makes it easier to
model, integrate and query any data sources, build data pipelines, and integrate
data in real-time. A data fabric also streamlines deriving insights from data
through better data observability and data quality by automating manual tasks
across data platforms using machine learning. ... The data mesh architecture is
an approach that aligns data sources by business domains, or functions, with
data owners. With data ownership decentralization, data owners can create data
products for their respective domains, meaning data consumers, both data
scientist and business users, can use a combination of these data products for
data analytics and data science.
Embracing the Platinum Rule for Data

It’s much easier to innovate around one platform and one set of data. Making
this a business and not an IT imperative, you can connect data into the
applications that matter. For example, creating a streamlined procure-to-pay and
order-to-cash process is possible only because we’ve broken down data silos. We
are now capable of distributing new customer orders to the optimum distribution
facility based on the final destination and available inventory in minutes vs.
multiple phone calls and data entry in multiple systems that previously would
have taken hours and resources. The speed and effectiveness of these processes
has led to multiple customer awards. Our teams need to store data in ways that
is harmonized before our users start to digest and analyze the information.
Today many organizations have data in multiple data lakes and data warehouses,
which increases the time to insights and increases the chance for error because
of multiple data formats. ... As data flows through Prism, we’re able to
visualize that same data across multiple platforms while being confident in one
source of the truth.
The Purpose of Enterprise Architecture
The primary purpose of the models is to facilitate the architect to understand
the system being examined. Understand how it works today, understand how it can
be most effectively changed to reach the aspirations of the stakeholders, and
understand the implications and impacts of the change. A secondary purpose is
re-use. It is simply inefficient to re-describe the Enterprise. The efficiency
of consistency is balanced against the extra energy to describe more than is
needed, and to train those who describe and read the descriptions on formal
modeling. The size, geographic distribution, and purpose of the EA team will
dramatically impact the level of consistency and formality required. Formal
models are substantially more re-usable than informal models. Formal models are
substantially easier to extend across work teams. The penalty is that formal
models require semantic precision. For example, regardless of the structure of
an application in the real world, it must be represented in a model conforming
to the formal definition. This representation is possible with a good model
definition.
Staying Agile: Five Trends for Enterprise Architecture

Continuous improvement is a cornerstone of agile digital business design.
Organizations want to deliver more change, with higher quality results,
simultaneously. Progressive, mature EAs are now designing the system that builds
the system, redesigning and refactoring the enterprise’s way-of-working. This
goal is a fundamental driver for many of these trends. In the pursuit of this
trend, it’s important to remember that the perfect business design isn’t easily
achievable. Trying one approach, learning through continuous feedback and making
adjustments is a rinse and repeat process. For example, a business might use the
Team Topologies technique to analyze the types of work that teams are performing
and then reorganize those teams to in order to minimize cognitive loads – for
instance by assigning one set of teams to focus on a particular value stream
while others focus solely on enabling technical capabilities. These adjustments
might need to happen multiple times until the right balance is found to ensure
optimal delivery of customer value and team autonomy.
Blockchain and GDPR

Given that the ruling grants EU persons the right to contest automated
decisions, and smart contracts running on a blockchain are effectively making
automated decisions, the GDPR needs to be taken in to account when developing
and deploying smart contracts that use personal data in the decision making
process, and produce a legal effect or other similarly significant effect.Smart
contract over-rides. The simplest means of ensuring smart contract compliance is
to include code within the contract that allows a contract owner to reverse any
transaction conducted. There are however a number of problems that could arise
from this. ... As the appeal time can be long, many such actions may have been
taken after the original contract decision, and it may not even be possible to
roll back all the actions. Consent and contractual law. A second approach is to
ensure that the users activating the smart contract are aware that they are
entering into such a contract, and that they provide explicit consent. The GDPR
provides the possibility of waiving the contesting of automated decisions under
such terms, but the smart contract would require putting on hold any subsequent
actions to be taken until consent is obtained.
Quote for the day:
"Making good decisions is a crucial
skill at every level." -- Peter Drucker
No comments:
Post a Comment