So you want to change cloud providers

Cloud has never really been about saving money. It’s about maximizing
flexibility and productivity. As one HN commenter points out, “I work on a very
small team. We have a few developers who double as ops. None of us are or want
to be sysadmins. For our case, Amazon’s ECS [Elastic Container Service] is a
massive time and money saver.” How? By removing sysadmin functions the team
previously had to fill. “Yes, most of the problems we had before could have been
solved by a competent sysadmin, but that’s precisely the point—hiring a good
sysadmin is way more expensive for us than paying a bit extra to Amazon and just
telling them ‘please run these containers with this config.’ ” He’s doing cloud
right. Others suggest that by moving to serverless options, they further
reduce the need for sysadmins. Yes, the more you dig into services that are
unique to a particular cloud, the less easy it is to migrate, no matter how many
credits a provider throws at you. But, arguably, the less desire you’d have to
migrate if your developers are significantly more productive because they’re not
reinventing infrastructure wheels all the time.
How Not to Do Digital Transformation (Hint: It’s How Not to Do Data Integration, Too)
Digital transformation poses a set of difficult data management problems. How do
you integrate data that originates in separate, sometimes geographically
far-flung locations? Or, more precisely, how do you integrate data that is
widely distributed in geophysical and virtual space in a timely manner? This
last is one of the most misunderstood problems of digital transformation.
Software vendors, cloud providers, and, not least, IT research firms talk a lot
about digital transformation. Much of what they say can safely be ignored. In an
essential sense, however, digital transformation involves knitting together
jagged or disconnected business workflows and processes. It entails digitizing
IT and business services, eliminating the metaphorical holes, analog and
otherwise, that disrupt their delivery. It is likewise a function of cadence and
flow: i.e., of ensuring that the digital workflows which underpin core IT and
business services function smoothly and predictably; that processes do not
stretch – grind to a halt as they wait for data to be made available or for work
to be completed – or contract, i.e., that steps in a workflow are not skipped if
resources are unavailable.
The Internet of Things in Solutions Architecture
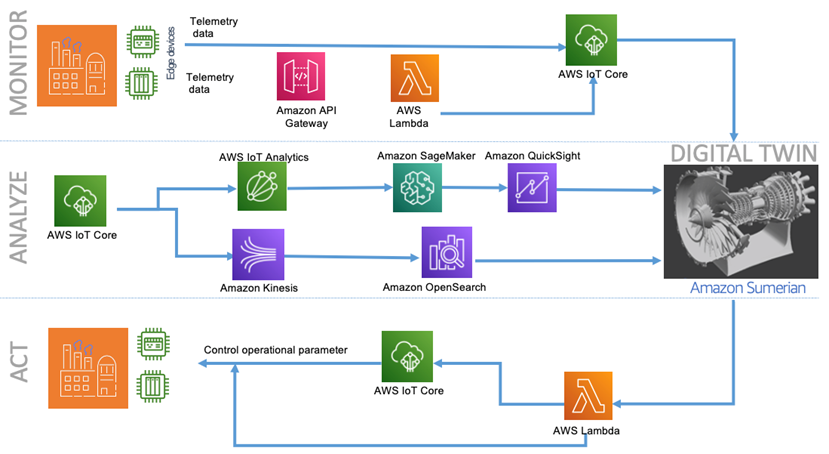
Industrial customers seek to gain insights into their industrial data and
achieve outcomes such as lower energy costs, detecting and fixing equipment
issues, spotting inefficiencies in manufacturing lines, improving product
quality, and improving production output. These customers are looking for
visibility into operational technology (OT) data from machines and product life
cycles (PLCs) systems for performing root cause analysis (RCA) when a production
line or a machine goes down. Furthermore, IoT improves production throughput
without compromising product quality by understanding micro-stoppages of
machinery in real time. Data collection and organization across multiple
sources, sites, or factories are challenging to build and maintain.
Organizations need a consistent representation of all their assets that can be
easily shared with users and used to build applications, at a plant, across
plants, and at a company level. Data collected and organized using on-premises
servers is isolated to one plant. Most data collected on-premises is never
analyzed and thrown away due to a lack of open and accessible data.
10 NFT and cryptocurrency security risks that CISOs must navigate

When someone buys an NFT, they aren't actually buying an image, because storing
photos in the blockchain is impractical due to their size. Instead, what users
acquire is some sort of a receipt that points them to that image. The blockchain
only stores the image's identification, which can be a hash or a URL. The HTTP
protocol is often used, but a decentralized alternative to that is the
Interplanetary File System (IPFS). Organizations who opt for IPFS need to
understand that the IPFS node will be run by the company that sells the NFT, and
if that company decides to close shop, users can lose access to the image the
NFT points to. ... A blockchain bridge, sometimes called cross-chain bridge,
does just that. "Due to their nature, usually they are not implemented strictly
using smart contracts and rely on off-chain components that initiate the
transaction on the other chain when a user deposits assets on the original
chain," Prisacaru says. Some of the biggest cryptocurrency hacks involve
cross-chain bridges, including Ronin, Poly Network, Wormhole.
How to achieve better cybersecurity assurances and improve cyber hygiene

Don’t believe that network engineers are immune to misconfiguring devices
(including firewalls, switches, and routers) when making network changes to meet
operational requirements. Human error creates some of the most significant
security risks. It’s typically not the result of malicious intent – just an
oversight. Technicians can inadvertently misconfigure devices and, as a result,
they fall out of compliance with network policy, creating vulnerabilities. If
not monitored closely, configuration drift can result in significant business
risk. ... Network segmentation is a robust security measure often underutilized
by network security teams. In the current threat landscape with increasingly
sophisticated attacks, the successful prevention of network breaches cannot be
guaranteed. However, a network segmentation strategy, when implemented
correctly, can mitigate those risks by effectively isolating attacks to minimize
harm. With a well-planned segmented network, it is easier for teams to monitor
the network, identify threats quickly and isolate incidents.
‘It Depends’ — Kubernetes Excuse or Lack of Actionable Data?

Finding the right answer more quickly needs to be easier. It needs to require
fewer cycles and get us to a higher degree of confidence in our answer. If we
have an assured way to get there, we’re more likely to lean in — “It depends”
and “I have a way to get the answer we need to make an informed decision.”
Sure, there’s the initial discomfort (and stomach lurch) of the inverted loop,
but there’s also a way to come out of it with a positive experience while you
go along for the ride. The question then becomes how? In the past, the only
way to identify all of the variables, understand the dependencies and their
impact, and then make an informed decision was to approach it manually. We
could do that by observation or experimentation, two approaches to learning
that have their place in the application optimization process. But let’s be
honest, a manual approach is just not viable, both in terms of the resources
needed and the high level of confidence needed in the results — not to mention
the lack of speed. Fortunately, today, machine learning and automation can
help.
How to Maximize Your Organization's Cloud Budget

To optimize a cloud budget, start with the smallest possible allowable
instance that's capable of running an application or service, recommends
Michael Norring, CEO of engineering consulting firm GCSIT. “As demand
increases, horizontally scale the application by deploying new instances
either manually or with auto-scaling, if possible.” Since cloud service costs
increase exponentially the larger the size of the service, it's generally
cheaper and more affordable to use small instances. “This is why when
deploying services, it's better to start with a fresh install, versus
lifting-and-shifting the application or service with all its years of cruft,”
he says. ... Many enterprises already use multiple clouds from various
providers, observes Bernie Hoecker, partner and enterprise cloud
transformation lead with technology research and advisory firm ISG. He notes
that adopting a multi-cloud estate is an effective strategy that allows an
organization to select providers on the basis of optimizing specific
applications. Enterprises also turn to multiple clouds as a mechanism to deal
with resiliency and disaster recovery, or as a hedge to prevent vendor
lock-in. “A multi-cloud estate makes IT management and governance complex,”
Hoecker observes.
Cybersecurity is IT’s Job, not the Board’s, Right?
Directors should prepare ahead of time to prevent the effects of cyberattacks
and mitigate the risk of personal liability. Broadly speaking, boards must
implement a reporting system and monitor or oversee the operation of that
system to prevent personal liability under Caremark. In re Caremark Int’l Inc.
Derivative Litig., 698 A.2d 959, 970 (Del. Ch. 1996). In Caremark,
shareholders filed a derivative suit against the board after the company was
required to pay approximately $250 million for violations of federal and state
health care laws and regulations. Id. at 960–61. The Delaware Chancery Court
held that directors can be held personally liable for failing to
“appropriately monitor and supervise the enterprise.” Id. at 961. The court
emphasized that the board must make a good faith effort to implement an
adequate information and reporting system and that the failure to do so can
constitute an “unconsidered failure of the board to act in circumstances in
which due attention would, arguably, have prevented the loss.” Id. at 967.
While Caremark did not address cybersecurity directly, the court’s reasoning
in Caremark is applicable to board involvement, or lack thereof, with
cybersecurity.
5 Types of Cybersecurity Skills That IT Engineers Need

Since IT engineers are typically the people who configure cloud environments,
understanding these risks, and how to manage them, is a critical cybersecurity
skill for anyone who works in IT. This is why IT operations teams should learn
the ins and outs of cloud security posture management, or CSPM, the discipline
of tools and processes designed to help mitigate configuration mistakes that
could invite security breaches. They should also understand cloud
infrastructure entitlement management, which complements CSPM by detecting
types of risks that CSPM alone can't handle. ... Even well-designed networks
that resist intrusion can be vulnerable to distributed denial of service, or
DDoS, attacks, which aim to take workloads offline by overwhelming them with
illegitimate network requests. To keep workloads operating reliably then, IT
operations engineers should have at least a working knowledge of anti-DDoS
techniques and tools. Typically, anti-DDoS strategies boil down to deploying
services that can filter and block hosts that may be trying to launch a DDoS
attack.
EncroChat: France says ‘defence secrecy’ in police surveillance operations is constitutional
France’s Constitutional Council, which includes former prime ministers Laurent
Fabius and Alain Juppé among its members, heard arguments on 29 March over
whether the EncroChat and Sky ECC hacking operations were compatible with the
right to a fair trial and the right to privacy guaranteed under the French
constitution. At issue is a clause in the criminal code that allows
prosecutors or magistrates to invoke “national defence secrecy” to prevent the
disclosure of information about police surveillance operations that defence
lawyers argue is necessary for defendants to receive a fair trial. French
investigators used article 707-102-1 of the criminal code – described as a
“legal bridge” between French police and the secret services – to ask France’s
security service, DGSI, to carry out surveillance operations on two encrypted
phone systems, EncroChat and Sky ECC. Patrice Spinosi, lawyer at the
Council of State and the Supreme Court, representing the Association of
Criminal Lawyers and the League of Human Rights, said the secret services
hacking operation had struck a gold mine of information.
Quote for the day:
"Successful leaders see the
opportunities in every difficulty rather than the difficulty in every
opportunity" -- Reed Markham
No comments:
Post a Comment