How enterprise architects need to evolve to survive in a digital world

Traditionally, enterprise architects needed to be able to translate business
needs into IT requirements or figure out how to negotiate a better IT system
deal. That’s still important, but now they also need to be able to talk to board
members and executive teams about the business implications of technology
decisions, particularly around M&A. If the CEO wants to be able to acquire
and divest new companies every year, the enterprise architect needs to explain
the system landscape that requires, and in a merger context, what systems to
merge and how. If the company invests in a new enterprise resource planning
(ERP) system, the enterprise architect should be able to articulate the
implications and the effect on the P&L. This level of conversation cannot be
based on boxes and diagrams on PowerPoint, which is often the default but a
largely theoretical approach. Instead, enterprise architects have to be able to
use practical “business” language to communicate and articulate the ROI of
architecture decisions and how they contribute to business-outcome key
performance indicators.
New Android Malware Uses VNC to Spy and Steal Passwords from Victims
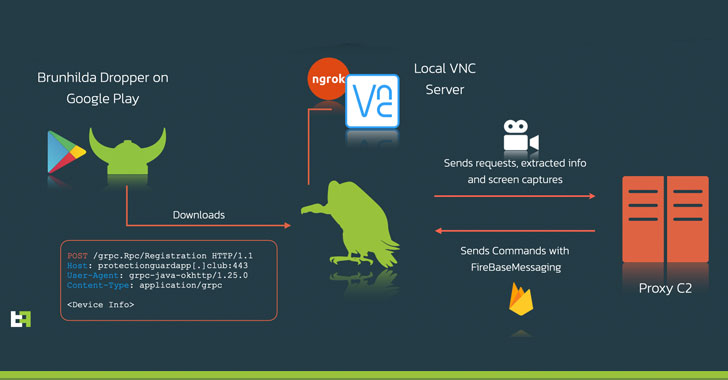
"The actors chose to steer away from the common HTML overlay development we
usually see in other Android banking Trojans: this approach usually requires a
larger time and effort investment from the actors to create multiple overlays
capable of tricking the user. Instead, they chose to simply record what is shown
on the screen, effectively obtaining the same end result." ... What's more, the
malware employs ngrok, a cross-platform utility used to expose local servers
behind NATs and firewalls to the public internet over secure tunnels, to provide
remote access to the VNC server running locally on the phone. Additionally, it
also establishes connections with a command-and-control (C2) server to receive
commands over Firebase Cloud Messaging (FCM), the results of which, including
extracted data and screen captures, are then transmitted back to the server.
ThreatFabric's investigation also connected Vultur with another well-known piece
of malicious software named Brunhilda, a dropper that utilizes the Play Store to
distribute different kinds of malware in what's called a "dropper-as-a-service"
(DaaS) operation, citing overlaps in the source code and C2 infrastructure used
to facilitate attacks.
DevOps still 'rarely done well at scale' concludes report after a decade of research
A cross-functional team is one that spans the whole application lifecycle from
code to deployment, as opposed to a more specialist team that might only be
concerned with database administration, for example. Are cross-functional teams
a good thing? "It depends," Kersten said. "There are underlying strata of
technology that are better off centralized, particularly if you've got
regulatory burdens, but that doesn't mean you shouldn't have cross-functional
teams … too far in either direction is definitely terrible. The biggest problem
we see is if there isn't a culture of sharing practices amongst each other." One
thing to avoid, said Kersten, is a DevOps team. "I think we've broken the term
DevOps team inside organisations," he told us. "I think it has passed beyond
useful … calling your folk DevOps engineers or cloud engineers, these sorts of
imprecise titles are not particularly useful, and DevOps is particularly
broken." What if an organization reads the report and realises that it is not
good at public cloud and not effective at DevOps, what should it do? "First
optimize for the team," said Kersten.
DeepMind Launches Evaluation Suite For Multi-Agent Reinforcement Learning

Melting Pot is a new evaluation technique that assesses generalisation to novel
situations that consist of known and unknown individuals. It can test a broad
range of social interactions such as cooperation, deception, competition, trust,
reciprocation, stubbornness, etc. Unlike multi-agent reinforcement learning
(MARL) that lacks a broadly accepted benchmark test, single-agent reinforcement
learning (SARL) has a diverse set of benchmarks suitable for different purposes.
Further, MARL has a relatively less favourable evaluation landscape compared to
other machine learning subfields. Melting pot offers a set of 21 MARL
multi-agent games or ‘substrates’ to train agents on and more than 85 unique
test scenarios for evaluating these agents. A central equation–
Substrate+Background Population=Scenario–captures the true essence of the
Melting pot technique. The term substrate refers to a partially observable
general sum Markov game; a Melting Pot substrate is a game of imperfect
information that each player possesses which is unknown to their co-players. It
includes the layout of the map, how objects are located, and how they
move.
What to Look for When Scaling Your Data Team
Today, data-driven innovation has become a strategic imperative for just about
every company, in every industry. But as organizations expand their investment
in analytics, AI/ML, business intelligence, and more, data teams are struggling
to keep pace with the expectations of the business. Businesses will only
continue to rely more heavily on their data teams. However, recent survey
research suggests that 96% of data teams are already at or over their work
capacity. To avoid leaving their teams in a lurch, many organizations will need
to significantly scale their data team’s operations, both in terms of
efficiencies and team size. In fact, 79% of data teams indicated that
infrastructure is no longer the scaling problem — this puts the focus on people
and team capacity. But what should managers look for when growing their teams?
And what tools can provide relief for their already overburdened staff? The
first step that managers of data teams must do is to evaluate their teams’
current skills in close alignment with the projected needs of the business.
Doing so can provide managers with a deeper understanding of what skill sets to
look for when interviewing candidates.
Eight Signs Your Agile Testing Isn’t That Agile

When you have a story in a sprint, and you find an issue with that story, what
do you do? For many teams, the answer is still “file a defect.” In waterfall
development, test teams would get access to a new build with new features all at
once. They would then start a day-, week-, or even month-long testing cycle.
Given the amount of defects that would be found and the time duration between
discovery and fixing, it was critical to document every single one. This
documentation is not necessary in Agile development. When you find an issue,
collaborate with the developer and get the issue fixed, right then and there, in
the same day or at least in the same sprint. If you need to persist information
about the defect, put it in the original story. There is no need to introduce
separate, additional documentation. There are only two reasons you should create
a defect. One: an issue was found for previously completed work, or for
something that is not tied to any particular story. This issue needs to be
recorded as a defect and prioritized. (But, see next topic!)
Mitre D3FEND explained: A new knowledge graph for cybersecurity defenders

D3FEND is the first comprehensive examination of this data, but assembling it
wasn’t without its difficulties. Using the patent database as original source
material for this project was both an inspiration and a frustration.
Kaloroumakis got the idea when he had to review patent filings when he was CTO
of Bluvector.io, a security company, before he came to Mitre. “There is an
incredible variance in technical specifics across the patent collection,” he
says. “With some patents, little is left to your imagination, but others are
more generic and harder to figure out.” He was surprised at the thousands of
cybersecurity patent filings he found. “Some vendors have more than a hundred
filings,” he said and noted that he has not cataloged every single cybersecurity
patent in the collection. Instead, he has used the collection as a means to an
end, to create the taxonomies and knowledge graph for the project. He also
wanted to emphasize that just because a technology or a particular security
method is mentioned in a patent filing doesn’t mean that this method actually
finds its way into the actual product.
Benefits of Loosely Coupled Deep Learning Serving
Another convincing aspect of choosing a message-mediated DL serving is its easy
adaptability. There exists a learning curve for any web framework and library
even for micro-frameworks such as Flask if one wants to exploit its full
potential. On the other hand, one does not need to know the internals of
messaging middleware, furthermore all major cloud vendors provide their own
managed messaging services that take maintenance out of the engineers’ backlog.
This also has many advantages in terms of observability. As messaging is
separated from the main deep learning worker with an explicit interface, logs
and metrics can be aggregated independently. On the cloud, this may not be even
needed as managed messaging platforms handle logging automatically with
additional services such as dashboards and alerts. The same queuing mechanism
lends itself to auto-scalability natively as well. Stemming from high
observability, what queuing brings is the freedom to choose how to auto-scale
the workers. In the next section, an auto-scalable container deployment of DL
models will be shown using KEDA
Should You Trust Low Code/No Code for Mission-Critical Applications?

More enterprises now understand the value of low code and no code, though the
differences between those product categories are worth considering. Low code is
aimed at developers and power users. No code targets non-developers working in
lines of business. The central idea is to get to market faster than is possible
with traditional application development. ... In some cases, it makes a lot of
sense to use low code, but not always. In Frank's experience, an individual
enterprise's requirements tend to be less unique than the company believes and
therefore it may be wiser to purchase off-the-shelf software that includes
maintenance. For example, why build a CRM system when Salesforce offers a
powerful one? In addition, Salesforce employs more developers than most
enterprises. About six years ago, Bruce Buttles, digital channels director at
health insurance company Humana, was of the opinion that low code/no code
systems "weren't there yet," but he was ultimately proven wrong. "I looked at
them and spent about three months building what would be our core product, four
or five different ways using different platforms. I was the biggest skeptic,"
said Buttles.
Confidence redefined: The cybersecurity industry needs a reboot
As businesses continue to adjust to the virtual and flex workplace, a common
fear is loss of productivity and, ultimately, damage to their bottom line. While
many enterprises were already on a “digital transformation” journey, this new
dynamic has added the need for fresh thinking. As a result, many organizations
are implementing new applications to ensure day-to-day activities remain
seamless, but are unknowingly — or, in some cases, knowingly — sacrificing
security in the process. This is an expansive area of risk for many businesses.
Truth be told, the human (and even non-human) workforce will always come with a
certain risk level, but now a distributed workforce often provides malicious
actors with more opportunities to do their dirty work; most organizations have
created a larger “attack surface” as a result of the pandemic. To allow their
businesses to thrive going forward, the key for leaders in both IT and business
is to focus on enablement and security – providing access to important
technology and tools but properly controlling access to keep your business and
your customers’ critical assets protected.
Quote for the day:
"Leadership is familiar, but not well
understood." -- Gerald Weinberg
No comments:
Post a Comment