How Synthetic Data Levels The Playing Field

Synthetic data can be defined as data not collected from real-world events.
Today, specific algorithms are available to generate realistic synthetic data
used as a training dataset. Deep Generative Networks/Models can learn the
distribution of training data to generate new data points with some variations.
While it is not always possible to learn the models’ exact distribution,
algorithms can come close. ... The big players already have a stronghold on data
and have created monopolies or ‘data-opolies’. Synthetic data generation models
can address this power imbalance. Secondly, the rising number of cyberattacks,
especially after the pandemic, has raised privacy and security concerns. The
situation is especially worrying when huge amounts of data are stored in one
place. By creating synthetic data, organisations can mitigate this risk.
Thirdly, whenever datasets are created, they reflect real-world biases,
resulting in the over-representation or under-representation of certain sections
of society. The machine learning algorithms based on such datasets amplify such
biases resulting in further discrimination. Synthetic data generation can fill
in the holes and help in creating unbiased datasets.
Researchers Discover Two Dozen Malicious Chrome Extensions
While malicious extensions are an issue with all browsers, it's especially
significant with Chrome because of how widely used the browser is, Maor says.
It's hard to say what proportion of the overall Chrome extensions currently
available are malicious. It's important to note that just a relatively small
number of malicious extensions are needed to infect millions of Internet users,
he says. One case in point was Awake Security's discovery last June of over 100
malicious Google Chrome extensions that were being used as part of a massive
global campaign to steal credentials, take screenshots, and carry out other
malicious activity. Awake Security estimated that there were at least 32 million
downloads of the malicious extensions. In February 2020, Google removed some 500
problematic Chrome extensions from its official Chrome Web Store after being
tipped off to the problem by security researchers. Some 1.7 million users were
believed affected in that incident. In a soon-to-be-released report, Cato says
it analyzed five days of network data collected from customer networks to see if
it could identify evidence of extensions communicating with command-and-control
servers.
What IT Leaders Need to Know About Open Source Software

Despite conventional wisdom, open-source solutions are, by their nature, neither
more nor less secure than proprietary third-party solutions. Instead, a
combination of factors, such as license selection, developer best practices and
project management rigor, establish a unique risk profile for each OSS
solution.The core risks related to open source include: Technical risks,
including general quality of service defects and security
vulnerabilities; Legal risks, including factors related to OSS license
compliance as well as potential intellectual property
infringements; Security risks, which begin with the nature of OSS
acquisition costs. The total cost of acquisition for open source is virtually
zero, as open-source adopters are never compelled to pay for the privilege of
using it. Unfortunately, one critical side effect of this low burden of
acquisition is that many open-source assets are either undermanaged or
altogether unmanaged once established in an IT portfolio. This undermanagement
can easily expose both quality and security risks because these assets are not
patched and updated as frequently as they should be. Finally, vendor lock-in can
still be a risk factor, given the trend among vendors to add proprietary
extensions on top of an open-source foundation (open core).
Applying Stoicism in Testing
To consider and look for the unknown information about a system, you need to
have justice. In Stoicism, this stands for “showing kindness and generosity in
our relationships with others”. And because you don’t know everything, you need
other people to help you out. Gathering information is also about creativity, so
you have to gather inspiration from past experience, and with your colleagues
must be able to connect dots that weren’t connected before. Once I even stated,
“The knowledge (and information) you gather as a tester about the software can
be an interesting input for new software products and innovations”. But as a
Stoic, stay humble ;-). After gathering all the information you need, you should
use your wisdom (“based on reasoning and judgment”) to come to conclusions so
that you can answer the question “Is this software ready to be used?” Although
our customers are the best testers, we as testers are in the position that we
are (or at least should be) able to answer the question at every step in the
software development: if the software is going to production, what can happen?
The information you put on the table for your stakeholder should be based on
facts.
Data Analyst vs. Data Scientist
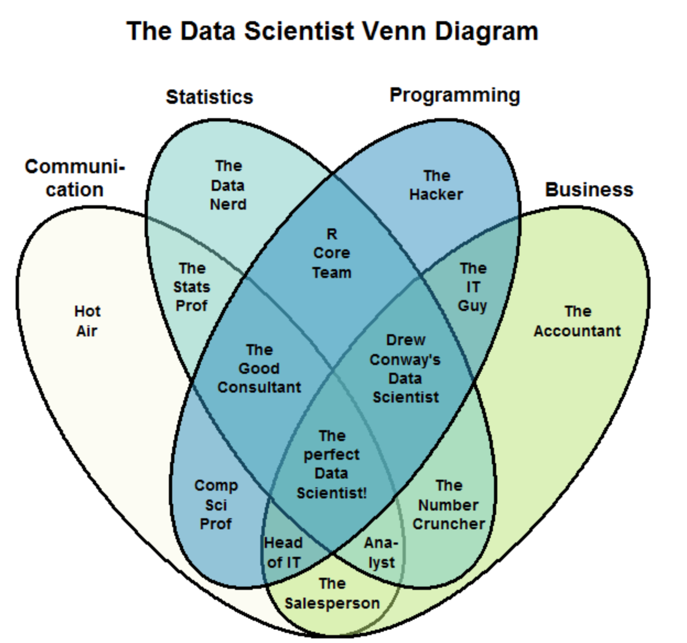
The typical data analyst role is consulting-centric, as can be seen from the
Indeed job spec example. What they are preoccupied with for the most part is
wrangling data from Excel spreadsheets and SQL databases, extracting
insightful conclusions via retrospective analyses, A/B tests, and generally
providing evidence-based business advice. The last point illustrates why
reporting routines with visualisation tools such as Tableau are as pivotal as
pivoted tables. Data modelling on the other hand is often limited to basic
supervised learning or its stats equivalent: regression analysis. ... To be
fair, data scientists are for that reason expected to be more than analytical
wizards. They are supposed to be builders who employ advanced programming to
create pipelines that predict and recommend in production environments with
near perfect accuracy. Compared with analysts, who’re like investigative
reporters, they are a lot more product development than consulting oriented.
Although it’s also required of a data scientist to provide data-led commercial
advice. Some say the title was coined to manifest that the role was a
confluence of three fields: maths/statistics, computer science and domain
expertise.
Tech projects for IT leaders: How to build a home lab

If you're like most technology leaders, the closest you get to the actual
technology you select and manage is creating PowerPoint decks that tell others
about the performance, maintenance and updating of that technology. There's
nothing fundamentally wrong with this of course; you can be a fantastic leader
of a construction firm without having swung a hammer, or a cunning military
strategist who has never rucked over a hill or fired a weapon. However,
hands-on time with the fundamental building blocks of your domain can make you
a better leader, just as the architect who spends time in the field and
understands the materials and building process makes him or her more effective
at creating better structures. ... Think of a home lab as the technology
equivalent of the scientist's laboratory. It's a place where you can
experiment with new technologies, attempt to interconnect various services in
novel ways and quickly clean things up when you're done. While you might be
picturing a huge rack of howling servers, fortunately for us you can now
create the equivalent of a small data center on a single piece of physical
equipment.
IOTA still wants to build a better blockchain, and get it right this time

What went wrong then, and how is IOTA going to fix it -- besides introducing a
new wallet? Schiener focused on some key technical decisions that proved
wrong, and are being retracted. IOTA wanted to be quantum-proof, and that's
why it used a "special cryptography," as Schiener put it. IOTA's cryptography
only allowed, for example, to utilize an address once. Reusing an address
could lead to a loss of funds. Another questionable decision was choosing to
use ternary, rather than binary encoding for data. That was because, according
to Schiener, the hypothesis of the future was that ternary is a much better
and more efficient way to encode data. The problem is, as he went on to add,
that this also needs ternary hardware to work. There are more, having to
do with the way the ledger is created. It's still a DAG, but it has different
algorithms. Schiener said that over the last one and a half years, IOTA has
been reinvented and rewritten from the ground up. This new phase of the
project is Chrysalis, which is this new network upgrade. With Chrysalis, IOTA
is also moving toward what it calls Coordicide.
Browser powered scanning in Burp Suite

One of the main guiding principles behind Burp’s new crawler is that we should
always attempt to navigate around the web applications behaving as much as
possible like a human user.. This means only clicking on links that can
actually be seen in the DOM and strictly following the navigational paths
around the application (not randomly jumping from page to page).Before we had
browser-powered scanning, the crawler (and the old spider) essentially
pretended to be a web browser. It was responsible for constructing the
requests that are sent to the server, parsing the HTML in the responses, and
looking for new links that could be followed in the raw response we observed
being sent to the client. This model worked well in the Web 1.0 world, where
generally the DOM would be fully constructed on the server before being sent
over the wire to the browser. You could be fairly certain that the DOM
observed in an HTTP response was almost exactly as it would be displayed in
the browser. As such, it was relatively easy to observe all the possible new
links that could be followed from there.Things start to break down with this
approach in the modern world.
Fintech disruption of the banking industry: innovation vs tradition?

The first was the rise of the internet. Constantly improving speeds and
widespread access meant hundreds of millions of consumers were suddenly able
to access digital services. The second was the rise of the smartphone. This
hardware transformed consumer behaviour beyond recognition. Apps and other
software products providing significant upfront value made smartphones
indispensable — just think of Shopify, Google Maps and Uber. The third driver
which paved the way for fintech providers’ success was the financial crisis in
2008. Not only did this bring the traditional banking system to the brink of
collapse, but consumers were far less trusting of the big banks thereafter.
The new breed of financial services providers was not tied down by legacy
infrastructures and, with smaller teams and flexible IT infrastructures, they
were more agile. And this allowed them to easily circumnavigate the new
regulatory and compliance requirements that were introduced in the wake of the
financial downturn. Fintech providers sought to solve problems the banks could
not. Or at least to do what the banks do, but better.
Top 3 Cybersecurity Lessons Learned From the Pandemic
As the world began relying on these new digital capabilities, new risks and
challenges were introduced. Organizations that were well-equipped to extend
visibility and control to this new way of working found themselves in a far
better situation than those that were scrambling to completely reengineer
their security capabilities. The ones that had built an empowered and
proactive security team, backed by robust processes and supported by effective
technology, were able to adapt and overcome. Organizations that were locked
into a rigid operational model, overly reliant on vendor platforms or lacking
a defined set of processes to support their new reality, struggled to keep
pace. ... Since the pandemic began, we have seen an increased emphasis and
shift toward zero trust and security access service edge (SASE) principles.
With strong identity and access management capabilities, insights into
services and APIs, and visibility into remote endpoint devices, security teams
can put themselves in position for rapid and effective responses — even within
this unique virtual setting. Access to sensitive and confidential data is the
new perimeter for an organization's cybersecurity posture.
Quote for the day:
"A tough hide with a tender heart is a
goal that all leaders must have." -- Wayde Goodall
No comments:
Post a Comment