Enterprise Infrastructure Management Requires the Right Strategy for Success

The first step is to simplify the environment. Beyond just the four categories outlined above, IT organizational and cultural shifts need to change. Streamlining the environment takes planning, time and effort. Look for solutions and approaches that further simplify the environment. At the same time, consider how these changes impact your processes and organizational structure. Not all of the changes will be based in technology. As the demands of your customers change, so will your organization and processes. Look for opportunities to address technical debt and remove old or un-needed processes. These two steps alone go a long way toward simplification. Part of simplification includes the introduction of automation. In the past, organizations faced the fact that they had to do everything themselves. This was partly due to a lack of mature and sophisticated solutions along with the ability to add more people to resolve issues. Today, that approach simply is no longer feasible. Humans cannot keep up with the rate of change. Solutions are far more mature and sophisticated than those of the past.
AI, Machine Learning, and the Basics of Predictive Analytics for Process Management
There are certain machine learning applications where you can achieve a high accuracy. If you’re doing image processing, and you use deep learning – a type of machine learning – and it’s trying to identify, “Is this a picture of a cat or is it a picture of a dog?” It turns out that just like humans, computers can also do that very well if given the right training data and you apply the right machine learning methods. There are also things out there that, regardless of how advanced the machine is, or how intelligent the human is, neither the machine nor the human can make accurate predictions about exactly which customer is going to cancel. But what you can do is draw the trends and assign probabilities. That’s the job of the predictive model: to assign probabilities of who is more or less likely to show whatever outcome or behavior you’re trying to predict. So you determine what would be helpful to predict, and then you find out, “I can’t predict accurately, but wow, I can predict a lot better than guessing.” Probably, in many cases, better than any human could because of all of this data at the computer’s disposal.
Cybersecurity stocks savaged for a second week as Symantec results disappoint

Symantec shares finished the week down 7.1% at $19.25, after a 7.8% decline Friday. Of the 29 analysts who cover Symantec, two have buy ratings on the stock, 25 have hold ratings, and two have sell ratings. Following earnings, analysts’ average share-price target fell to $21.05 from $23.36, according to FactSet data. Cowen analyst Gregg Moskowitz, who has an underperform rating on the stock, called it “another highly disappointing quarter” for Symantec. Jefferies analyst John DiFucci, who has a hold rating, said the company faces notable challenges in its enterprise business, namely its SEP 14 endpoint protection product and the Blue Coat Secure Web Gateway business. In a note, DiFucci said “in endpoint, the company faces a multitude of private upstarts as competitors offering modern solutions that are competitive with SEP 14. Similarly, in the Secure Web Gateway market, the company continues to face direct competition from companies such as Zscaler and iboss, and indirect competition from the next-generation firewall vendors offering URL filtering functionalities that are considered ‘good enough’ to meet the needs of some enterprises.”
GDPR: What's really changed so far?
While some users will have chosen to give their consent, many will have withdrawn it and others may not have been able to explicitly give it as emails were lost in old in-boxes or junk mail folders -- for organisations, that led to the same result as opting out. "The opt-in environment can only have reduced business volume in the activity of direct marketing -- it can't have made it go up, it can only make it go down," said Stewart Room, lead partner for GDPR and data protection at PwC. "What it has done is it's increased awareness. There was more outreach done on data protection in the months of May and June 2018 in Europe than has ever been done in the entirety of the world in the history of data protection," said Room. While there's a focus on organisations like Facebook and Google which are well known for using data as a product for generating revenue, they're far from the only ones which have been hit by GDPR.
‘Moneyball’ing data – A closer look at how churn and propensity models work

So how does a propensity to buy model work? Similar to the churn model, it looks at past behavior, attributes, demographics, sales data, etc. of the best customers in your training data that you want more of. For example, there is a set of thousand customers that are your real cash cows and spend $1000+ on your merchandise every month. This becomes the protagonist that you are going to refer to and compare the rest of your training data set with. Let’s say that one of the patterns that the model detected was that majority of the customers that bought $1k+ merchandise were loyal to one specific brand in your store. This purchase pattern becomes a base for you to start marketing to others that have bought that specific brand but are in the $700 per month bucket. (What do you market to them? Look at the basket of the $1k+). This is just one example. Propensity models can slice and dice your data to look at attributes, behavior, and patterns that might be so counterintuitive that a human can never see a connection between them.
The impact of cloud migration strategies on security and governance
Most of these decisions are about governance and risk management. With lift and shift, the application functionality is pretty clear, but bringing that out to the cloud introduces data risks and technical risks. Data controls may be insufficient, and the application’s architecture may not be a good match for cloud, leading to poor performance and high cost. One group of SaaS applications stems from ‘shadow IT’. The people that adopt them typically pay little attention to existing risk management policies. These can also add useless complexity to the application landscape. The governance challenges for these are obvious: consolidate and make them more compliant with company policies. Another group of SaaS applications is the reincarnation of the ‘enterprise software package’. Think ERP, CRM or HR applications. These are typically run as a corporate project, with all its change management issues, except that you don’t have to run it yourself.
Oracle vs. Hadoop
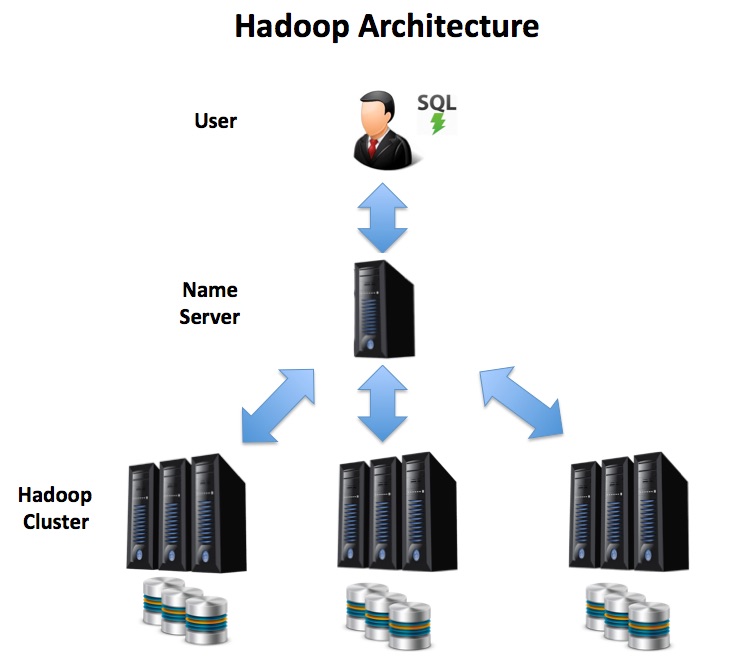
Despite sophisticated caching techniques, the biggest bottleneck for most Business Intelligence applications is still the ability to fetch data from disk into memory for processing. This limits both the system processing and it’s ability to scale — to quickly grow to deal with increasing data volumes. As there’s a single server, it also needs expensive redundant hardware to guarantee availability. This will include dual redundant power supplies, network connections and disk mirroring which, on very large platforms can make this an expensive system to build and maintain. Compare this with the Hadoop Distributed Architecture below. In this solution, the user executes SQL queries against a cluster of commodity servers, and the entire process is run in parallel. As effort is distributed across several machines, the disk bottleneck is less of an issue, and as data volumes grow, the solution can be extended with additional servers to hundreds or even thousands of nodes. Hadoop has automatic recovery built in such that if one server becomes unavailable, the work is automatically redistributed among the surviving nodes, which avoids the huge cost overhead of an expensive standby system.
10 Dark Web warning signs that your organization has been breached
In the wake of seemingly constant high profile breaches, organizations are taking precautions to protect against cyberattacks, including raising security budgets and educating employees. However, the cost of a breach can be enough to significantly harm a company's finances and reputation: The average total cost of a data breach is $3.86 million, according to a recent Ponemon Institute report. The ongoing risk of attack has led some organizations to seek new ways to proactively monitor the Dark Web for lost or stolen data, according to a Wednesday report from Terbium Labs. ... Dark Web and clear web sites like Pastebin are a dumping ground for personal, financial, and technical information with malicious intent, the report said. There is often a motivation behind these posts, such as political beliefs, hacktivism, vigilantism, or vandalism. For example, the executive of a wealth management firm was included in a large-scale dox as the result of their political contributions, the report noted.
Agile: Reflective Practice and Application
By focusing on your own local efficiency, which can lead to focusing on what is not needed, can mean at best doing nothing for the larger system and at worst making the larger system less efficient. The obsession with coding efficiency in particular kills a great many software products. I see teams actually proud of a growing pile of stories in need of testing, or a team dedicated to front-end UI, proud of having endless features complete against mocks and how the back-end teams can’t keep up. Sadly, these teams seem oblivious to the fact that they are not adding value to the system. Let me give an example that a friend of mine shared recently: My friend was baking some cakes for an event and needed to bake 10 cakes, but only had one oven. Her husband offered to help out and so she asked him to measure out the ingredients for the cakes in advance so that it would be quicker to get the next cake in the oven. When she came to get the ingredients for the cake, they were not ready, her husband had optimised for himself and not for the goal.
An IT operating model for the digital age
Consider a typical IT team – generally, all tech staff will sit in their own division, removed from the rest of the business because it is easier to track, manage and budget their work. What happens, then, if the head of customer experience has a request? It is unlikely that customer experience teams, which have different key performance indicators (KPIs), will have much interaction with IT. The result is two frustrated parties lacking a common language and unable to deliver innovation at the pace required by customers and the wider business. The challenge is to reorganise team structures in a way that allows innovation to flourish. In the era of digital transformation 1.0, that meant a bolt-on or “bi-modal” approach to digital, essentially giving a dedicated team the resources and licence to operate at pace, while the rest of the business continued plodding along in a traditional environment. It is not a bad place to start to get digital initiatives prioritised, but the reality is that “digital” now impacts every transaction and every touchpoint.
Quote for the day:
"If you don't understand that you work for your mislabeled 'subordinates,' then you know nothing of leadership. You know only tyranny." -- Dee Hock
No comments:
Post a Comment