How Machine Learning, A.I. Might Change Education

One area in which A.I. intersects with student learning is in ethics. Some studies are already exploring the ethical issues of replacing teachers with bots. However, although bots can enhance education, they can’t replace teachers, according to Bernhardt L. Trout, professor of chemical engineering and director of Society, Engineering, and Ethics at the Massachusetts Institute of Technology. Trout argues that A.I. can enrich the learning of students as they master skills, languages and basic math, but it can’t help students learn creativity or critical thinking. “Bots will not be able to decide for us what is good, although they might be able to help us learn better the issues around the decision of what is good,” he said. “Bots are limited in making certain choices about education in ways that human beings are not limited, so this is where we get into the more ethical issues.” Trout sees bots teaching themes or the usage of certain words, for example, but they may be limited in helping students critique literature. He believes a bot is unable to teach the essential concepts needed to understand the work of philosophers such as Plato or Dante, or painters such as Michelangelo: “That’s where I think there is an intrinsic limitation.”
Rethinking change control in software engineering

When organizations mandate that their ops teams focus solely on stability, change control can quickly become change prevention, much to the chagrin of development teams that are mandated to continuously update and deliver new features. With DevOps now inverting the traditional IT delivery model, the question becomes: Can change control still work in the way it was intended? It's likely that small, software-focused organizations running in the cloud won't use the term change control. They may just execute deployments when it makes sense, especially if the team doesn't yet charge for their services, or they have a way to turn a new service on for only a limited number of users. On the other end, large organizations that still run COBOL tend to use monolithic ticketing systems to manage permissions and change approvals. However, most teams probably find themselves somewhere in the middle of these two extremes, leaving them in a place where they need to find a realistic balance between both the resiliency and flexibility of feature deployments.
What is the internet backbone and how it works

Like any other network, the internet consists of access links that move traffic to high-bandwidth routers that move traffic from its source over the best available path toward its destination. This core is made up of individual high-speed fiber-optic networks that peer with each other to create the internet backbone. The individual core networks are privately owned by Tier 1 internet service providers (ISP), giant carriers whose networks are tied together. These providers include AT&T, CenturyLink, Cogent Communications, Deutsche Telekom, Global Telecom and Technology (GTT), NTT Communications, Sprint, Tata Communications, Telecom Italia Sparkle, Telia Carrier, and Verizon. By joining these long-haul networks together, Tier 1 ISPs create a single worldwide network that gives all of them access to the entire internet routing table so they can efficiently deliver traffic to its destination through a hierarchy of progressively more local ISPs. In addition to being physically connected, these backbone providers are held together by a shared network protocol, TCP/IP. They are actually two protocols, transport control protocol and internet protocol that set up connections between computers, insuring that the connections are reliable and formating messages into packets.
Working from home: Your common challenges and how to tackle them

Interruptions come from outside, like a knock at the door from a delivery driver asking you to take in a parcel for a neighbour. Other potential interruptions; family and pets and friends who fail to understand that just because you are at home, you are still working. Closed doors, do not disturb signs and noise-cancelling headphones all come in handy. More working from home tips here. Distractions are slightly different. These are mostly the result of being in a different environment to the one which you are used to, and that means habits are disrupted and priorities get muddled. In the office your priorities are (mostly) well defined – you're there to work. At home your priorities are different; having fun, cooking, eating, cleaning, watching TV – almost by definition everything not work related. Bringing work into the home, especially if it's for the first time, especially now, confuses all of this. It also makes you think you can combine the two, which is why you'll try to wash the dishes while on a conference call (and yes, everyone will know). Here the solution is around building a new work routine so that focusing is easier. That's why every set of remote working tips talks about getting up and getting dressed, and attempting to work regular hours.

Keith Fricke, principal consultant at tw-Security, notes that it's critical for healthcare entities to take a number of critical security measures when using telemedicine applications. That includes ensuring the transmission of information over the internet is encrypted and making sure that the endpoints where telehealth transmissions begin and end are secured, he notes. "I don't think these risks are heightened by the coronavirus," he says. "However, a rush to establish new telehealth applications or a rush to expand existing ones to meet demands driven by COVID-19 can lead to overlooking important controls necessary to maintain security and privacy of information. "As with any technology deployment involving the storage, processing or transmission of PHI or other confidential information, it is important to implement telehealth services with the appropriate technical, physical and administrative controls." As the use of telemedicine expands in dealing with the outbreak, new risks will also evolve, Fricke adds.
When Will 100% Remote Be an Accepted Norm?
Picture yourself graduating from college in the 1980s or 1990s, ready to change the world with your college degree and your freshly polished programming skills. Depending on the year you started working in the industry, you might have to share a terminal to write the program code required to complete your job. The idea of having a computer at your desk wasn't a reality. For those starting a little later, you might have a computer at your desk, but it is merely a client to a host system housing your program logic and processing power. The system you programmed on was in near proximity to you. Later, that idea was broken into an application server and some type of data store or database. There wasn't a cloud option to host your system, but some did have custom connectivity to align data centers across private corporate networks. Remember, the internet wasn't a "thing" we could rely on, yet. There was a fleet of programmers who grew up in this reality.
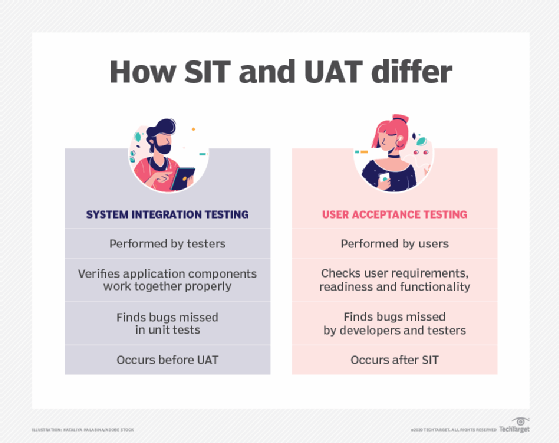
With user acceptance testing, the development organization gives the build or release to the target consumer of the system, late in the software development lifecycle. Either the end users or that organization's product development team perform expected activities to confirm or accept the system as viable. The UAT phase is typically one of the final steps in an overall software development project. ... Testers who evaluate functionality as it's delivered are usually prepared to also check application functionality as a whole, integrated solution. SIT is often a more technical testing process than UAT. Testers design and execute SIT, as they've become familiar with the types of defects common in the application throughout the SDLC. The SIT phase precedes UAT. Because the technical expertise between users and testers varies significantly, the two demographics are likely to find vastly different defects between UAT and SIT. SIT often uncovers bugs unit tests didn't catch -- defects that rely on a workflow or interaction between two application components, such as a sequential order of operations.
How Red Hat tackles security

In the just-released Red Hat Product Security Report 2019, Red Hat said it's seeing more customers than ever trying to grapple with ever-mounting security issues by using third-party scanners. But, he said, "While scanning tools can provide a useful 'single pane of glass' view of vulnerabilities across an enterprise-wide environment, they generally do a poor job of articulating risks specific to a technology or implementation." So, Red Hat Engineering and Red Hat Product Security both explain exactly what's what with security issues and making Red Hat's "upstream packages enterprise-ready by regression testing, hardening, and tweaking the package to meet our customers' unique business demands and our release standards." To help improve this process, Red Hat made a fairly sizable change to Red Hat Enterprise Linux (RHEL) support life cycle. Because "RHEL is the foundation of all of our products and services, we felt it was important to expand the scope of what we supported." So, RHEL now includes patches and fixes for Important-rated issues, which typically cover the largest share of issues. Previously, Red Hat was more selective about which Important-rated issues were addressed in RHEL's Extended Update Support.
Banks are adopting account aggregator framework on data

Account aggregators are responsible for transferring, but not storing, client data. An AA ecosystem, as envisaged by the Reserve Bank of India (RBI), would be a platform for financial services companies to reach out to the consumer to seek consent before using their personal data to optimise their product offerings. "All the work is going in that direction. We are coordinating between the ecosystems. The scale-up will see a hockey stick effect. These banks and AA companies are part of the first wave. Many are waiting to join the second wave," said BG Mahesh, a cofounder of Sahamati, a non-profit collective of account aggregators. So far, Cams Finserv, FinSec AA Solutions and Cookiejar Technologies have received operating licences from the Reserve Bank of India. Kotak Mahindra Group said it was launching a pilot among 50,000 employees to test use cases for the AA framework in banking, broking, wealth management, and insurance. "As we speak we are launching a pilot with our employees before we launch it for our customers.
Making Your Code Faster by Taming Branches

Most software code contains conditional branches. In code, they appear in if-then-else clauses, loops, and switch-case constructs. When encountering a conditional branch, the processor checks a condition and may jump to a new code path, if the branch is taken, or continue with the following instructions. Unfortunately, the processor may only know whether a jump is necessary after executing all instructions before the jump. For better performance, modern processors predict the branch and execute the following instructions speculatively. It is a powerful optimization. There are some limitations to speculative execution, however. For example, the processor must discard the work done after the misprediction and start anew when the branch is mispredicted. Thankfully, processors are good at recognizing patterns and avoiding mispredictions, when possible. Nevertheless, some branches are intrinsically hard to predict and they may cause a performance bottleneck. Programmers can be misled into underestimating the cost of branch mispredictions when benchmarking code with synthetic data that is either too short or too predictable.
Quote for the day:
"You can't lead anyone else further than you have gone yourself." -- Gene Mauch
No comments:
Post a Comment