Don’t worry about shadow IT. Shadow IoT is much worse

So far so good. But this reasoning emphatically does not carry over to the emerging practice of shadow IoT, which has become a growing concern in the last year or so. Basically, we are talking about when people in your organization add internet-connected devices (or worse, entire IoT networks!) without IT’s knowledge. Those renegades are likely seeking the same speed and flexibility that drove shadow IT, but they are taking a far bigger risk for a much smaller reward. Shadow IoT takes shadow IT to another level, with the potential for many more devices as well as new types of devices and use cases, not to mention the addition of wholly new networks and technologies. According to a 2018 report from 802 Secure, “IoT introduces new operating systems, protocols and wireless frequencies. Companies that rely on legacysecurity technologies are blind to this rampant IoT threat. Organizations need to broaden their view into these invisible devices and networks to identify rogue IoT devices on the network, visibility into shadow-IoT networks, and detection of nearby threats such as drones and spy cameras.”
GraphQL: Evolution of Modern Age Database Management System
Consider we have an API that is consumed by a responsive web application. Depending upon the device where the app has opened, the data displayed on the screen will vary, some fields may be hidden on smaller screen devices and all the fields may be shown on devices with a larger screen. The following infographic explains various pain points, pertaining to manage data returned when using REST: With GraphQL, it’s just a matter of querying the fields that are required depending upon the device. The front end is in control of the data it requests, and the same principles can be utilized for any GraphQL API. With GraphQL, we can easily aggregate data from different sources and serve it up to the users under a single umbrella rather than making multiple REST calls from the front end or back end. We can expose a legacy system through a unified API. As mentioned above, every GraphQL API is composed of types, schema and resolvers. In order to create an API, we require to create a GraphQL server in some language. As you know by now, GraphQL is a language in its own and has a specification, the specification must be implemented in a programming language to be utilized.
Cybercriminals Leveraging Evasion And Anti-Analysis Techniques To Avoid Detection

Many modern malware tools already incorporate features for evading antivirus or other threat detection measures, but cyber adversaries are becoming more sophisticated in their obfuscation and anti-analysis practices to avoid detection. For example, a spam campaign demonstrates how adversaries are using and tweaking these techniques against defenders. The campaign involves the use of a phishing email with an attachment that turned out to be a weaponized Excel document with a malicious macro. The macro has attributes designed to disable security tools, execute commands arbitrarily, cause memory problems, and ensure that it only runs on Japanese systems. One property that it looks for in particular, an Excel Date variable, seems to be undocumented. Another example involves a variant of the Dridex banking trojan which changes the names and hashes of files each time the victim logs in, making it difficult to spot the malware on infected host systems. The growing use of anti-analysis and broader evasion tactics is a reminder of the need for multi-layered defenses and behavior-based threat detection.
Security pros reiterate warning against encryption backdoors

“We know that encryption backdoors dramatically increase security risks for every kind of sensitive data, and that includes all types of data that affects our national security. The IT security community overwhelmingly agrees that encryption backdoors would have a disastrous impact on the integrity of our elections and on our digital economy as a whole.” Opponents of encryption backdoors have said repeatedly that government-mandated weaknesses in encryption systems put the privacy and security of everyone at risk the same backdoors can be exploited by hackers. The survey also shows that 70% of the Black Hat USA respondents believe countries with government-mandated encryption backdoors are at an economic disadvantage in the global marketplace, while 84% would never knowingly use a device or program from a company that agreed to install a backdoor. Bocek added: “On a consumer level, people want technology that prioritises the security and privacy of their personal data. ...”
For Sale on Cybercrime Markets: Real 'Digital Fingerprints'
The marketplace says it too has listings from vetted vendors selling "bot logs with fingerprints" for PayPal, Pornhub and Facebook accounts; U.S. and Canadian bank accounts; cryptocurrency hot and cold wallets; and AirBnB accounts. "All the logs we provide come with full fingerprint data," an advertisement for the site boasts. "This means exactly that. We provide all the cookie & browsing history in each log to ensure you have success with all your operations. Once you load the cookies onto your selected browser you will become the identical user from the log you have just purchased from us. This ensures a much higher success rate and anonymity for your business needs. We provide you with a free browser where you can just upload your purchased log and use it with simplicity." Registration for Richlogs costs $50, payable via bitcoin or monero, after which the site says a user will receive $100 in site credit. Log data starts at $1 per record.vThe site also says that it can give users real-time access to hacked PCs so they can use them to remotely emulate victims via a SOCKS5 proxy.
Open-source spyware makes it on the Google Play Store

"The malicious functionality in AhMyth is not hidden, protected, or obfuscated," said Lukáš Štefanko, malware researcher at ESET, who conducted the investigation into the malicious app. "For this reason, it is trivial to identify the Radio Balouch app - and other derivatives - as malicious and classify them as belonging to the AhMyth family." "Nothing special was used to bypass either Google's IP or postpone the malicious function. I think it wasn't detected because users first had to set up the app - set the language, allow permissions, go through a couple of 'next' buttons, for an app overview and only then would the malicious code be launched," he told ZDNet. Štefanko said ESET spotted two instances of the malware being uploaded on the Play Store, one on July 2, and the second on July 13. Both were removed within a day, but only after they contacted the Play Store staff. While the two apps never managed to get more than 100 installs, the problem here was the fact that they ended up on the Play Store using nothing more than unobfuscated open-source code.
How IT departments can upskill in the new economy

Working in the gig economy works both for small businesses and startups, and large enterprises and public sector organisations. Yorkshire Water is one of the businesses mentioned in the TopCoders report. The water utility firm opened up 12 months of its data through the Leeds Open Data Institute to crowd-source the discovery of new trends or patterns. According to Yorkshire Water, it received a number of interesting submissions, such as an app proposal to use artificial intelligence (AI) to automate the recognition of leak noise, and a Fitbit-like device for monitoring water usage in household water pipes. New research has found that crowd-sourcing ideas for the smart use of public sector data offers a huge economic benefit. In July, the European Union (EU) reported that the total direct economic value of the data held in the public sector is expected to increase from a baseline of €52bn in 2018 to €194bn in 2030. Yorkshire Water recently sponsored a hackathon, in which software development teams were invited to take part in a competition focused on ideas for using open data to create a county-wide data dashboard for Yorkshire.
How to protect yourself and your organization against digital identity fraud

Continuously monitor digital identity markets. Monitoring these markets can help you identify compromised identities early so you can more diligently monitor traffic and/or enhance the verification methods for user logins. "Organizations can use services of threat intelligence companies such as IntSights to monitor their assets on markets such as Richlogs and Genesis," Ariel Ainhoren, head of research for IntSights, told TechRepublic. "Getting to them is not too complicated, and with decent protection measures such as a VPN, it is not too risky as well. But most small-medium organizations won't have the time to invest in monitoring these markets and the other dark web activity. They will usually notice that something is wrong only after threat actors will make use of these identities. This is what makes digital identity fraud and these markets so dangerous." Enable two-factor authentication. Asking for a second (or even third) variable to authenticate your users makes it more difficult for hackers to access your accounts. You might adopt a form of mobile verification or ask security questions that only the user would know.
Cloud Security: Mess It Up and It's on You
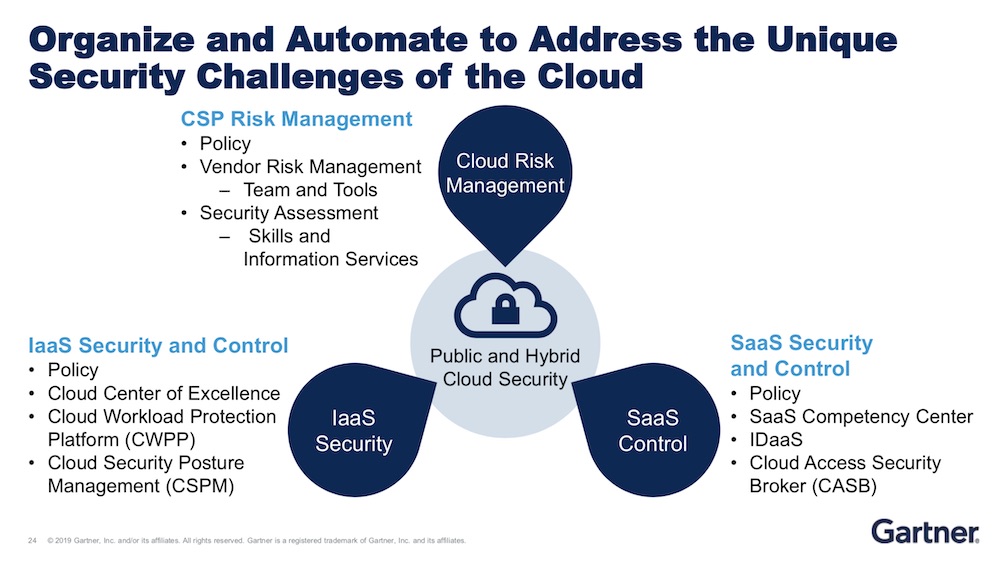
The majority of incidents are the result of errors and misconfigurations by cloud service providers' clients, Heiser says. That's due in part to how fundamental security practices of the past don't apply to cloud computing models. Take Capital One, a financial services company that's been one of the most aggressive in that vertical in embracing the cloud. A Seattle woman, Paige A. Thompson, is accused of taking advantage of a misconfigured firewall to gain access to more than 100 million credit card applications going back to 2003. She allegedly gained access credentials for a role with expansive permissions, including the area where the credit card applications were stored. AWS, Capital One's service provider, has indicated the problem wasn't on its side. "Security in the cloud is your responsibility, whether or not your cloud service provider makes it easy for you," Heiser says. "Cloud service providers do a great job of drawing the line between their responsibility and your responsibility. And so far, AWS has done a great job of always blaming their customers. So be forewarned."
Three Tips for Laying the Groundwork for Machine Learning
Despite on-premise IT infrastructure’s ability to host many open-source frameworks to create ML solutions, many organizations still lack the power and scalability to support them. If an organization is evaluating ML for a project, hyperscale cloud might be a good option to consider, since it offers consumption-based access to graphics processing unit (GPU) compute, which can dramatically accelerate the process of training a deep learning algorithm. Once the requirement moves from batch analysis to real time, the flow of relevant data must keep pace with ML algorithms working in near real-time. Ensuring that workloads are supported throughout a project’s lifecycle and organizations have the ability to experiment with ML capabilities is essential, and cloud elasticity can be used to address that. It has never been easier for organizations to expand into the cloud, as the big three public cloud providers -- AWS, Google and Amazon -- all fight for ML business. Despite this, organizations still lag behind in exploiting the elastic scalability of the cloud to derive value from their organization’s data with ML.
Quote for the day:
"The final test of a leader is that he leaves behind him in other men, the conviction and the will to carry on." -- Walter Lippmann
No comments:
Post a Comment