3 reasons cloud computing doesn’t save money

Without cloud spending visibility and insights, you’re basically driving a car
without a dashboard. You don’t how fast you’re going or when you’re about to run
out of gas. A guessing game turns into a big surprise when cloud spending is way
above what everyone initially thought. That sucking sound you hear is the value
that you thought cloud computing would bring now leaving the business. Second,
there is no discipline or accountability. A lack of cloud cost monitoring means
we can’t see what we’re spending. The other side of this coin is a lack of
accountability. Even when a business monitors cloud spending, that data is
useless if everyone knows there are no penalties. Why should people change their
behavior? They need known incentives to conserve cloud computing resources as
well as known consequences. Accountability problems can usually be corrected by
leadership making some unpopular decisions. Trust me, you’ll either deal with
accountability now or wait until later when it becomes much harder to fix.
How attackers use and abuse Microsoft MFA
The legitimate owner of a thusly compromised account is unlikely to spot that
the second MFA app has been added. “It is only obvious if one specifically looks
for it. If one goes to the M365 security portal, they will see it; but most
users never go to that place. It is where you can change your password without
being prompted for it, or change an authenticator app. In day-to-day use, people
only change passwords when mandated through the prompt, or when they change
their phone and want to move their authenticator app,” Mitiga CTO Ofer Maor told
Help Net Security. Also, an isolated, random prompt for the second
authentication factor triggered by the attacker can easily not be seen or
ignored by the legitimate account owner. “They get prompted, but once the
attacker authenticates on the other authenticator, that prompt disappears. There
is no popup or anything that says ‘this request has been approved by another
device’ (or something of that sort) to alert the user of the risk. ... ” Maor
noted.
The emergence of the chief automation officer

AI and automation can transform IT and business processes to help improve
efficiencies, save costs and enable people — employees — to focus on
higher-value work. Two of the most important areas of IT operations in the
enterprise are issue avoidance and issue resolution because of the massive
impact they have on cost, productivity, and brand reputation. The rapid digital
expansion among enterprises has led to an immediate uptick in demand from IT
leaders to embrace AIops tools to increase workflow productivity and ensure
proactive, continuous application performance. With AIops, IT systems and
applications are more reliable, and complex work environments can be managed
more proactively, potentially saving hundreds of thousands of dollars. This can
enable IT staff to focus on high-value work instead of laborious, time-consuming
tasks, and identify potential issues before they become major problems.
How a Service Mesh Simplifies Microservice Observability
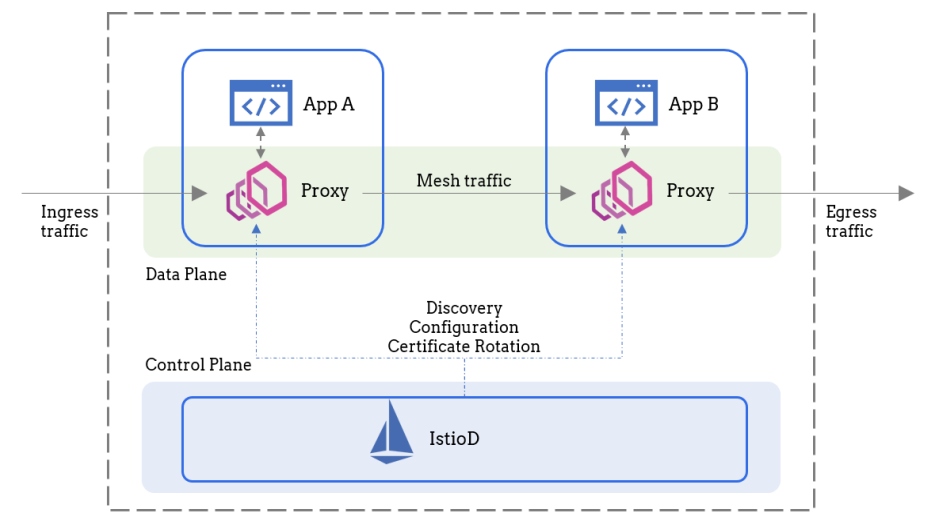
According to Jay Livens, observability is the practice to capture the system’s
current state based on the metrics and logs it generates. It’s a system that
helps us with monitoring the health of our application, generating alerts on
failure conditions, and capturing enough information to debug issues whenever
they happen. ... A major aspect of observability is capturing network telemetry,
and having good network insights can help us solve a lot of the problems we
spoke about initially. Normally, the task of generating this telemetry data is
up to the developers to implement. This is an extremely tedious and error-prone
process that doesn’t really end at telemetry. Developers are also tasked with
implementing security features and making communication resilient to failures.
Ideally, we want our developers to write application code and nothing else. The
complications of microservices networking need to be pushed down to the
underlying platform. A better way to achieve this decoupling would be to use a
service mesh like Istio, Linkerd, or Consul Connect.
IT talent: 4 interview questions to prep for

Whether managers have a more hands-on approach or allow their direct reports
more autonomy, identifying this during the interview process is in the best
interest of both parties. Additionally, some candidates thrive in an office,
while others are hoping for a completely remote position or even a hybrid
option. Discussing and defining preferences and working environments helps
clarify candidates’ expectations for their roles. It also benefits hiring
managers, prospective employees, and the companies, which can avoid high
turnover rates by being transparent in their recruiting phase. ... people
generally love to talk about things that make them proud. By asking this
question, hiring managers allow candidates to talk about who they are as
individuals rather than just what they bring to the larger business. Obviously,
pride can encompass past work projects, but some candidates might also cite
volunteer contributions, family achievements, or other accomplishments. Overall,
candidates should always be prepared to discuss experiences that have
contributed to their growth.
Beyond purpose statements

Many CEOs are starting to sound like politicians, throwing around lofty language
that is vague and hard to pin down. And therein lies the problem, or certainly
the challenge: to remain credible and trustworthy, leaders need to shift the
conversation from fuzzy purpose bromides to more tangible and concrete
statements about the impact their companies are having on society. That is not
simply a matter of semantics, as there is a world of difference between purpose
and impact. It is difficult to challenge a purpose. If a company says its reason
for existing in some form or fashion is to try to make the world a better place,
how can you pressure-test that claim? If that company is providing goods or
services that customers are willing to pay for, and it employs people and pays
vendors, then, ipso facto, it is doing something that has a perceived value. As
long as it’s not doing anything criminal or unethical, it’s working “to promote
the good of the people,” to borrow the language from one organization’s mission
statement. But if you are claiming that you are making an impact, then you need
proof. And that’s what makes a statement powerful.
Managing Expectations: Explainable A.I. and its Military Implications

AI systems can be purposefully programmed to cause death or destruction, either
by the users themselves or through an attack on the system by an adversary.
Unintended harm can also result from inevitable margins of error which can exist
or occur even after rigorous testing and proofing of the AI system according to
applicable guidelines. Indeed, even ‘regular’ operations of deployed AI systems
are mired with faults that are only discoverable at the output stage. ... A
primary cause for such faults is flawed training datasets and commands, which
can result in misrepresentation of critical information as well as unintended
biases. Another, and perhaps far more challenging, reason is issues with
algorithms within the system which are undetectable and inexplicable to the
user. As a result, AI has been known to produce outputs based on spurious
correlations and information processing that does not follow the expected rules,
similar to what is referred to in psychology as the ‘Clever Hans effect’.
POCs, Scrum, and the Poor Quality of Software Solutions
It is generally accepted that quality is the ‘reliability of a product’.
‘Reliability’ though, as we are used to think of in classical science, is the
attribute of consistently getting the same results under the same conditions. In
this classical view, building a Quality solution means that we should build a
product that never fails. Ironically, understanding reliability this way harms
Quality instead of achieving it. Aiming to build a product that never fails can
only result in extremely complex systems that are hard to maintain causing
Quality to degrade over time. The issue with reliability in this classical sense
is the false assumption that we control all conditions, while in fact we don’t
(hardware failure, network latency, external service throttling…etc.). We need
to extend the meaning of reliability to also accommodate for cases when the
conditions are not aligned: Quality is not only a measure of how reliable a
software product is when it is up & running, but also a measure of how
reliable it is when it fails.
Critical infrastructure is under attack from hackers. Securing it needs to be a priority - before it's too late

In order to protect networks – and people – from the consequences of attacks,
which could be significant, many of the required security measures are among
the most commonly recommended and often simplest practices. ... Cybersecurity
can become more complex for critical infrastructure, particularly when dealing
with older systems, which is why it's vital that those running them know their
own network, what's connected to it and who has access. Taking all of this
into account, providing access only when necessary can keep networks locked
down. In some cases, that might mean ensuring older systems aren't connected
to the outside internet at all, but rather on a separate, air-gapped network,
preferably offline. It might make some processes more inconvenient to manage,
but it's better than the alternative should a network be breached. Incidents
like the South Staffordshire Water attack and the Florida water incident show
that cyber criminals are targeting critical infrastructure more and more.
Action needs to be taken sooner rather than later to prevent potentially
disastrous consequences not just for organizations, but for people too.
How to Nurture Talent and Protect Your IT Stars

Anderson adds building out growth and learning opportunities starts with the
CTO. “That means ensuring we have learning and training goals identified,
which is used as a critical element for annual performance expectations of our
IT leaders and managers, not only for themselves, but for their staff,” he
says. As Court notes, the company invests internally through the LIFT
University with a cadre of continuing education and augmenting with external
training. “For career growth, I recommend IT teams have a close reporting or
partnership to the engineering and product teams,” Anderson adds. He says the
rationale for this is simple -- as employees want to perfect their craft, they
need to work for and with people that understand their craft, and push them to
continually learn through team, project, and program collaboration. “As we all
know, the one constant is that technology is constantly evolving, so
continuous learning for employees, especially our IT team, is a must,” he
says. SoftServe’s Semenyshyn says that closely monitoring employee burnout is
a priority across the IT industry, pointing out the advantage of the IT
business in a large global company is the possibility of rotations.
Quote for the day:
"Teamwork is the secret that make
common people achieve uncommon result." -- Ifeanyi Enoch Onuoha
No comments:
Post a Comment