Your mechanical keyboard isn't just annoying, it's also a security risk

If this has set you on edge then I have both good and bad news for you. The good
news is that while this is fairly creepy, it's unlikely that hackers will be
able to break into your private space and place a microphone in close enough
proximity to your keyboard without you noticing. The bad news is that there are
plenty of other ways that your keyboard could be giving away your private
information. Keystroke capturing dongles exist that can be plugged into a
keyboard’s USB cable, and wireless keyboards can be exploited using hardware
such as KeySweeper, a device that can record keyboards using the 2.4GHz
frequency when placed in the same room. There are even complex systems that use
lasers to detect vibrations or fluctuations in powerlines to record what's being
written on a nearby keyboard. Still, if you're a fan of mechanical keyboards
then don't let any of this deter you, especially if you use one at home rather
than in a public office environment. It's highly unlikely that you need to take
extreme measures in your own home and just about everything comes with a
security risk these days.
Relational knowledge graphs will transform business
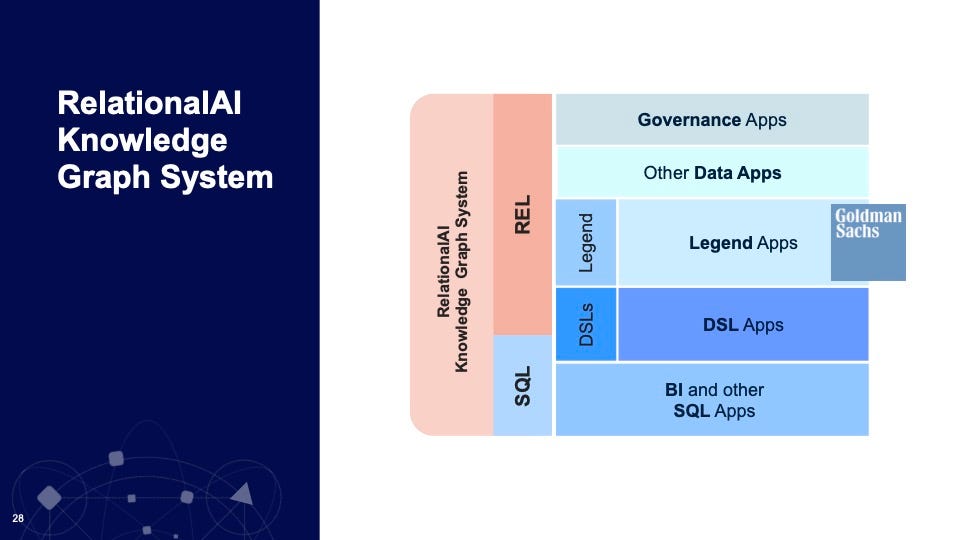
"There have been many generations of algorithms built that have all been created
around the idea of a binary one," said Muglia. "They have two tables with the
key to join the two together, and then you get a result set, and the query
optimizer takes and optimizes the order of those joins — binary join, binary
join, binary join!" The recursive problems such as Fred Jones's permissions, he
said, "cannot be efficiently solved with those algorithms, period." The right
structure for business relationships, as distinct from data relationships, said
Muglia, is a knowledge graph. "What is a knowledge graph?" asked Muglia,
rhetorically. He offered his own definition for what can be a sometimes
mysterious concept. "A knowledge graph is a database that models business
concepts, the relationships between them, and the associated business rules and
constraints." Muglia, now a board member for startup Relational AI, told the
audience that the future of business applications will be knowledge graphs built
on top of data analytics, but with the twist that they will use the relational
calculus going all the way back to relational database pioneer E.F. Codd.
We Need to Talk about the Software Engineer Grind Culture

SWE culture can be very toxic. Generally, I found that people who get rewarded
within software engineering are those who sacrifice their personal time for
their project/job. We reward people who code an entire project in 24 hours (I
mean, just think about the popularity of hackathons). I remember watching a
TikTok from a tech creator and he said that US software engineers are paid so
much not because of what they do during work hours, but because of all of the
extra work they do outside of it. Ask yourself: are you paid enough to sacrifice
your life outside of work? So many of us are conditioned to this rat race. I
realized that this grind has caused me to lose out on any hobbies outside of
coding. There are so many software engineers who are also tech creators on the
side. Whether they have a twitch channel dedicated to coding, making Youtube
videos about coding, or a tech content creator on TikTok, it usually has
something to do with this specialization in software engineering. The reason
these channels are so successful is because we, as software engineers, have
bought into this narrative.
Managing Tech Debt in a Microservice Architecture
This company has a lot of dedicated and smart engineers, which most probably
explains how they were able to come up with what they call the technology
capability plan. I find the TCP to be a truly innovative community approach to
managing tech debt. I've not seen anything like it anywhere else. That's why
I'm excited about it and want to share what we have learned with you. Here is
the stated purpose of the TCP. It is used by and for engineering to signal
intent to both engineering and product, by collecting, organizing, and
communicating the ever-changing requirements in the technology landscape for
the purposes of architecting for longevity and adaptivity. In the next four
slides of this presentation, I will show you how to foster the engineering
communities that create the TCP. You will learn how to motivate those
communities to craft domain specific plans for paying down tech debt. We will
cover the specific format and purpose of these plans. We will then focus on
how to calculate the risk for each area of tech debt, and use that for setting
plan priorities.
Shedding Light On Toil: Ways Engineers Can Reduce Toil

More proactive monitoring is another way to reduce toil, according to Englund
and Davis. “Responding to a crash loop is responding too late,” added Davis.
Instead, he advocated that SREs look toward leading indicators that suggest
the potential for failure so that teams can make adjustments well before
anything drastic occurs. If SLIs like error rate and latency are getting bad,
you must take reactive measures to fix them, causing more toil. Instead,
proactive monitoring is best to see the cresting wave before the flood.
Leading indicators could arise from following things like data queue
operations connected to servers or the saturation of a particular resource.
“If you can figure out when you’re about to fail, you can be prepared to
adapt,” said Davis. One major caveat of standardization is that you’re
inevitably going to encounter edge cases that require flexibility. And when an
outage or issue does arise, the remediation process is often very unique from
case to case. As a result, not all investment into standardization pays out.
Alternatively, teams that know how to improvise together are proven to be
better equipped for unforeseen incidents
Are your SLOs realistic? How to analyze your risks like an SRE
You can reduce the impact on your users by reducing the percentage of
infrastructure or users affected or the requests (e.g., throttling part of the
requests vs. all of them). In order to reduce the blast radius of outages,
avoid global changes and adopt advanced deployments strategies that allow you
to gradually deploy changes. Consider progressive and canary rollouts over the
course of hours, days, or weeks, which allow you to reduce the risk and to
identify an issue before all your users are affected. Further, having robust
Continuous Integration and Continuous Delivery (CI/CD) pipelines allows you to
deploy and roll back with confidence and reduce customer impact. Creating an
integrated process of code review and testing will help you find the issues
early on before users are affected. Improving the time to detect means that
you catch outages faster. As a reminder, having an estimated TTD expresses how
long until a human being is informed of the problem.
5 Ways to Drive Mature SRE Practices

Project failure — and the way it’s regarded within the organization — is often
as important as success. To create maximum value, SREs must be free to
experiment and work on strategic projects that push the boundaries,
understanding they will fail as often as they succeed. However, according to
the “State of SRE Report,” only a quarter of organizations accept the “fail
fast, fail often” mantra. To mature their practice, enterprises must free SREs
from the traditional cost constraints placed upon IT and encourage them to
challenge accepted norms. They should be setting new benchmarks for innovative
design and engineering practices, not be bogged down in the minutiae of
development cycles. Running hackathons and bonus schemes focused on
reliability improvements is a great way to uplevel SREs and encourage an
organizational culture of learning and experimentation, where failure is
valued as much as success. Measurement is critical to developing any IT
program, and SRE is no exception. To truly understand where performance gaps
are and optimize critical user journeys, SREs need to go beyond performance
monitoring data.
The Future of Data Management: It’s Already Here

Data fabric can automatically detect data abnormalities and take appropriate
steps to correct them, reducing losses and improving regulatory compliance. A
data fabric enables organizations to define governance norms and controls,
improve risk management, and improve monitoring—something that is increasing
in importance given legal standards for data governance and risk management
have become more demanding and compliance/governance vital. It also enhances
cost savings through the avoidance of potential regulatory penalties. A data
fabric represents a fundamentally different way of connecting data. Those who
have adopted one now understand that they can do many things differently,
providing an excellent route for enterprises to reconsider a host of issues.
Because data fabrics span the entire range of data work, they address the
needs of all constituents: developers, business analysts, data scientists, and
IT team members collectively. As a result, POCs will continue to grow across
departments and divisions.
Why Data Catalogs Are the Standard for Data Intelligence

Gartner positions a data catalog as the foundation “to access and represent
all metadata types in a connected knowledge graph.” To illustrate, I’ll share
a personal experience about why I think a data catalog is crucial to data
intelligence. Some years ago, when I worked at a large global technology
company, my manager said, “I want you to figure out what metrics we should
measure and tell us if our product is making our customers successful. We
don’t have the data or analysis today.” I was surprised. How could that be?
How can a successful enterprise not have the data model in place to measure a
market-leading product? Have they based their decisions on gut instinct? As
part of my work, I had to create some hypotheses, gather data, analyze it, and
create a recommendation. To start, I had to find an expert who had a
significant amount of tribal knowledge and could explain what data existed,
where it was located, what it meant, how I should use it, and what pitfalls I
might encounter when using it. Next, I had to get the data from the data
warehouse and write a lot of SQL queries, all while finding the data science
people to get their help.
An enterprise architecture approach to ESG
Often, and especially when looked at through a holistic enterprise
architecture approach, achieving or reporting on certain ESG goals (or seizing
on innovative new opportunities that ESG brings about) will not be possible
through isolated tech changes, but in fact, require a more holistic digital
transformation. An EA-supported ESG assessment will give an accurate view of
the costs and benefits of an organisation's overall IT portfolio. Architecture
lenses will then help to make the decisions necessary for ESG-related digital
investment and/or transformation. For example, the high energy footprint of
business IT systems is becoming an increasing focus of ESG concern.6,7 As a
consequence, organisations are feeling significant pressure to move to
‘clean-IT,' optimising the trade-off between energy consumption and
computational performance, and incorporating algorithmic and computational
efficiencies in IT solutions and designs. Meeting ESG future states will
likely require digitalisation and emerging technologies such as IoT, digital
twins, big data, and AI.
Quote for the day:
"At the heart of great leadership is a
curious mind, heart, and spirit." -- Chip Conley
No comments:
Post a Comment