How CIOs can unite sustainability and technology

CIOs must be proactive in progressing these organizational shifts, as business
leaders will continue to lean on them to ensure company technologies are
providing solutions without contributing to an environmental problem. While in
years past this was not an active concern, the information and communications
technology (ICT) sector has recently become a larger source of climate-related
impact. Producing only 1.5% of CO2 in 2007, the industry has now risen to 4%
today and will potentially reach 14% by 2040. Fortunately, CIOs can
course-correct by focusing on three key areas: Net zero - Utilize green software
practices that can reduce energy consumption; Trust - Build systems that
protect privacy and are fair, transparent, robust, and accessible;
and Governance - Make ESG the focus of technology, not an
afterthought. As a first step in this transition, CIOs can begin assessing
their organization’s technology through the lens of sustainability to ensure
that those goals are being thought about in every facet of the business. In
addition, they can connect with other leaders in the company to encourage
greater emphasis and dialogue in cross-organization planning for technology
solutions as they relate to sustainability targets.
Design patterns for asynchronous API communication
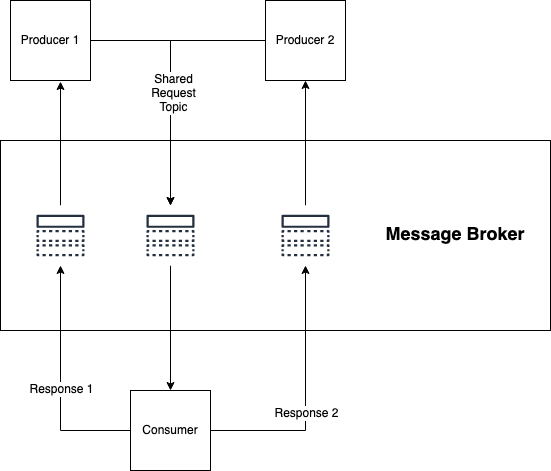
Request and response topics are more or less what they sound like:A client sends
a request message through a topic to a consumer; The consumer performs some
action, then returns a response message through a topic back to the consumer.
This pattern is a little less generally useful than the previous two. In
general, this pattern creates an orchestration architecture, where a service
explicitly tells other services what to do. There are a couple of reasons why
you might want to use topics to power this instead of synchronous APIs:You want
to keep the low coupling between services that a message broker gives us. If the
service that’s doing the work ever changes, the producing service doesn’t need
to know about it, since it’s just firing a request into a topic rather than
directly asking a service. The task takes a long time to finish, to the
point where a synchronous request would often time out. In this case, you may
decide to make use of the response topic but still make your request
synchronously. You’re already using a message broker for most of your
communication and want to make use of the existing schema enforcement and
backwards compatibility that are automatically supported by the tools used with
Kafka.
What is Data Gravity? AWS, Azure Pull Data to the Cloud

As enterprises create ever more data, they aggregate, store, and exchange this
data, attracting progressively more applications and services to begin analyzing
and processing their data. This “attraction” is caused, because these
applications and services require higher bandwidth and/or lower latency access
to the data. Therefore, as data accumulates in size, instead of pushing data
over networks towards applications and services, “gravity” begins pulling
applications and services to the data. This process repeats, which produces a
compounding effect, meaning that as the scale of data grows, it becomes
“heavier” and increasingly difficult to replicate and relocate. Ultimately, the
“weight” of this data being created and stored generates a “force” that results
in an inability to move the data, hence the term data gravity. Data gravity
presents a fundamental problem for enterprises, which is the inability to move
data at-scale. Consequently, data gravity impedes enterprise workflow
performance, heightens security & regulatory concerns, and increases
costs.
Windows 11 is getting a new security setting to block ransomware attacks

The new feature is rolling out to Windows 11 in a recent Insider test build, but
the feature is also being backported to Windows 10 desktop and server, according
to Dave Weston, vice president of OS Security and Enterprise at Microsoft.
"Win11 builds now have a DEFAULT account lockout policy to mitigate RDP and
other brute force password vectors. This technique is very commonly used in
Human Operated Ransomware and other attacks – this control will make brute
forcing much harder which is awesome!," Weston tweeted. Weston emphasized
"default" because the policy is already an option in Windows 10 but isn't
enabled by default. That's big news and is a parallel to Microsoft's default
block on internet macros in Office on Windows devices, which is also a major
avenue for malware attacks on Windows systems through email attachments and
links. Microsoft paused the default internet macro block this month but will
re-release the default macro block soon. The default block on untrusted macros
is a powerful control against a technique that relied on end users being tricked
into clicking an option to enable macros, despite warnings in Office against
doing so.
Untangling Enterprise API Architecture with GraphQL

GraphQL is a query language that allows you to describe your data requirements
in a more powerful and developer-friendly way than REST or SOAP. Its
composability can help untangle enterprise API architecture. GraphQL becomes the
communication layer for your services. Using the GraphQL specification, you get
a unified experience when interacting with your services. Every service in your
API architecture becomes a graph that exposes a GraphQL API. In this graph,
everyone who wants to integrate or consume the GraphQL API can find all the data
it contains. Data in GraphQL is represented by a schema that describes the
available data structures, the shape of the data and how to retrieve it. Schemas
must comply with the GraphQL specification, and the part of the organization
responsible for the service can keep this schema coherent. GraphQL composability
allows you to combine these different graphs — or subgraphs — into one unified
graph. Many tools are available to create such a “graph of graphs."
How The Great Resignation Will Become The Great Reconfiguration

We are witnessing a great reconfiguration of how employees expect to be treated
by employers. Henry Ford gave his workers a full two-day weekend as early as
1926, but now a weekend is expected in most office-based jobs—unless the job
involves serving customers over the weekend! We have certain expectations of the
employer and employee relationship, and what was normal before the pandemic is
now being challenged. Even Wall Street cannot hold back the tide. People expect
more flexibility over their hours and work location. Within a few years, this
will be normalized by the effect of the top talent expecting it and that
expectation fitering throughout company culture. This is how work will function
post-pandemic. The Great Resignation is the first step, but eventually, I
believe we will call the 2020s the Great Reconfiguration. ... WFH will live on -
You might want your team back in the office, but they know they can be more
productive remotely, and research backs up the employees. A new Harvard study
suggests that all that in-person time can be compressed into just one or two
days a week.
Will Your Cyber-Insurance Premiums Protect You in Times of War?

Due to the changing market and geopolitical situation, you need to be keenly
aware of the exact kind of cyber-insurance coverage your organization requires.
Your decisions should be dictated by the industry you're working in, the
security risk, and how much you stand to lose in the event of an attack. It's
important to note that insurance providers are also being more stringent in
their requirements for companies to even obtain cyber coverage in the first
place. Carriers are increasingly requiring companies to practice good cyber
hygiene and have rigid cybersecurity protocols in place before even offering a
quote. Once you have proper cybersecurity protocols in place, you should better
qualify for adequate plans. However, remember that no two plans are alike or
equally inclusive. When choosing a plan, be sure to look for any fine print
regarding act-of-war and terrorism exclusions or those for other "hostile acts."
Even when you've done everything right, your carrier can still attempt to deny
you coverage under these loopholes.
The new CIO playbook: 7 tips for success from day one
It’s possible that, up to now, your focus has been solely on technology. One of the big differentiators between working on an IT team, even in a leadership role, and being CIO is that you will need to understand how technology fits into the larger business goals of the company. You will need to be a technology translator and advocate for the CEO, business leadership, and board. For that, you have to understand the business first. “We can come up with creative technical solutions,” says Roberge. “We know you need an email system, a CRM system, and an ERP. But how does the business want to use those tools? How is the sales guy going sell product and be able to get a quote out, get the tax requirements, things like that?” Business leaders are unlikely to understand technology the way you do. So, you must understand the business in order to help the other business units, the CEO, and the board understand how technology can fit into their goals. “As technology experts, we know our technology extremely well,” says Roberge.
Explained: How to tell if artificial intelligence is working the way we want it to

Far from a silver bullet, explanation methods have their share of problems. For
one, Ghassemi’s recent research has shown that explanation methods can
perpetuate biases and lead to worse outcomes for people from disadvantaged
groups. Another pitfall of explanation methods is that it is often impossible to
tell if the explanation method is correct in the first place. One would need to
compare the explanations to the actual model, but since the user doesn’t know
how the model works, this is circular logic, Zhou says. He and other researchers
are working on improving explanation methods so they are more faithful to the
actual model’s predictions, but Zhou cautions that, even the best explanation
should be taken with a grain of salt. “In addition, people generally perceive
these models to be human-like decision makers, and we are prone to
overgeneralization. We need to calm people down and hold them back to really
make sure that the generalized model understanding they build from these local
explanations are balanced,” he adds.
Future-Proofing Organisations Through Transparency
Partners that trust each other, perform better. Both parties should clearly understand the decisions and actions they own. Consequently, organisations cooperate with less friction and enhance accessibility to relevant information. A study in the Harvard Business Review notes that managers frequently adopt a trust but verify approach, evaluating potential partner behaviours during negotiations to determine whether they are open and honest. As one manager in the study advised, “To see if [the] person is forthcoming; ask a question you know the answer to”. Transparent companies are viewed as ‘ethical’ as their customers believe they have nothing to hide. The new era of the business-to-business model demands transparency. Companies want to know that what they do matters and trace a project back to their organisation’s vision. In a modern world where sustainability is not just a buzzword, clients want to know that partnerships are built with brands that support their morals. Unsatisfied customers disengage with a company to find one that works together to achieve a greater outcome and takes accountability for their actions.
Quote for the day:
"People will not change their minds but
they will make new decisions based upon new information." --
Orrin Woodward






