CIOs contend with rising cloud costs

“A lot of our clients are stuck in the middle,” says Ashley Skyrme, senior
managing director and leader of the Global Cloud First Strategy and Consulting
practice at Accenture. “The spigot is turned on and they have these mounting
costs because cloud availability and scalability are high, and more businesses
are adopting it.” And as the migration furthers, cloud costs soon rank second —
next only to payroll — in the corporate purse, experts say. The complexity of
navigating cloud use and costs has spawned a cottage industry of SaaS providers
lining up to help enterprises slash their cloud bills. ... “Cloud costs are
rising,” says Bill VanCuren, CIO of NCR. “We plan to manage within the large
volume agreement and other techniques to reduce VMs [virtual machines].”
Naturally, heavy cloud use is compounding the costs of maintaining or
decommissioning data centers that are being kept online to ensure business
continuity as the migration to the cloud continues. But more significant to the
rising cost problem is the lack of understanding that the compute, storage, and
consumption models on the public cloud are varied, complicated, and often
misunderstood, experts say.
How WiFi 7 will transform business
In practice, WiFi 7 might not be rolled out for another couple of years —
especially as many countries have yet to delicense the new 6GHz spectrum for
public use. However, it is coming, and so it’s important to plan for this
development as plans could progress quicker than we first thought. In the same
way as bigger motorways are built and traffic increases to fill them, faster,
more stable WiFi will encourage more usage & users, and to quote the
popular business mantra: “If you build it…they will come….”. WiFi 7 is a
significant improvement over all the past WiFi standards. It uses the same
spectrum chunks as WiFi 6/6e, and can deliver data more than twice as fast. It
has a much wider bandwidth for each channel as well as a raft of other
improvements. It is thought that WiFi 7 could deliver speeds of 30 gigabits per
second (Gbps) to compatible devices and that the new standard could make running
cables between devices completely obsolete. It’s now not necessarily about what
you can do with the data, but how you actually physically interact with
it.
How to Innovate Fast with API-First and API-Led Integration

Many have assembled their own technologies as they have tried to deliver a
more productive, cloud native platform-as-a-shared-service that different
teams can use to create, compose and manage services and APIs. They try to
combine integration, service development and API-management technologies on
top of container-based technologies like Docker and Kubernetes. Then they add
tooling on top to implement DevOps and CI/CD pipelines. Afterward comes the
first services and APIs to help expose legacy systems via integration, for
example. When developers have access to such a platform within their preferred
tools and can reuse core APIs instead of spending time on legacy integration,
it means they can spend more time on designing and building the value-added
APIs faster. At best, a group can use all the capabilities because it spreads
the adoption of best practices, helps get teams ramped up faster and makes
them deliver quicker. But at the very least, APIs should be shared and
governed together.
Using Apache Kafka to process 1 trillion inter-service messages
One important decision we made for the Messagebus cluster is to only allow one
proto message per topic. This is configured in Messagebus Schema and enforced
by the Messagebus-Client. This was a good decision to enable easy adoption,
but it has led to numerous topics existing. When you consider that for each
topic we create, we add numerous partitions and replicate them with a
replication factor of at least three for resilience, there is a lot of
potential to optimize compute for our lower throughput topics. ... Making it
easy for teams to observe Kafka is essential for our decoupled engineering
model to be successful. We therefore have automated metrics and alert creation
wherever we can to ensure that all the engineering teams have a wealth of
information available to them to respond to any issues that arise in a timely
manner. We use Salt to manage our infrastructure configuration and follow a
Gitops style model, where our repo holds the source of truth for the state of
our infrastructure. To add a new Kafka topic, our engineers make a pull
request into this repo and add a couple of lines of YAML.
Load Testing: An Unorthodox Guide
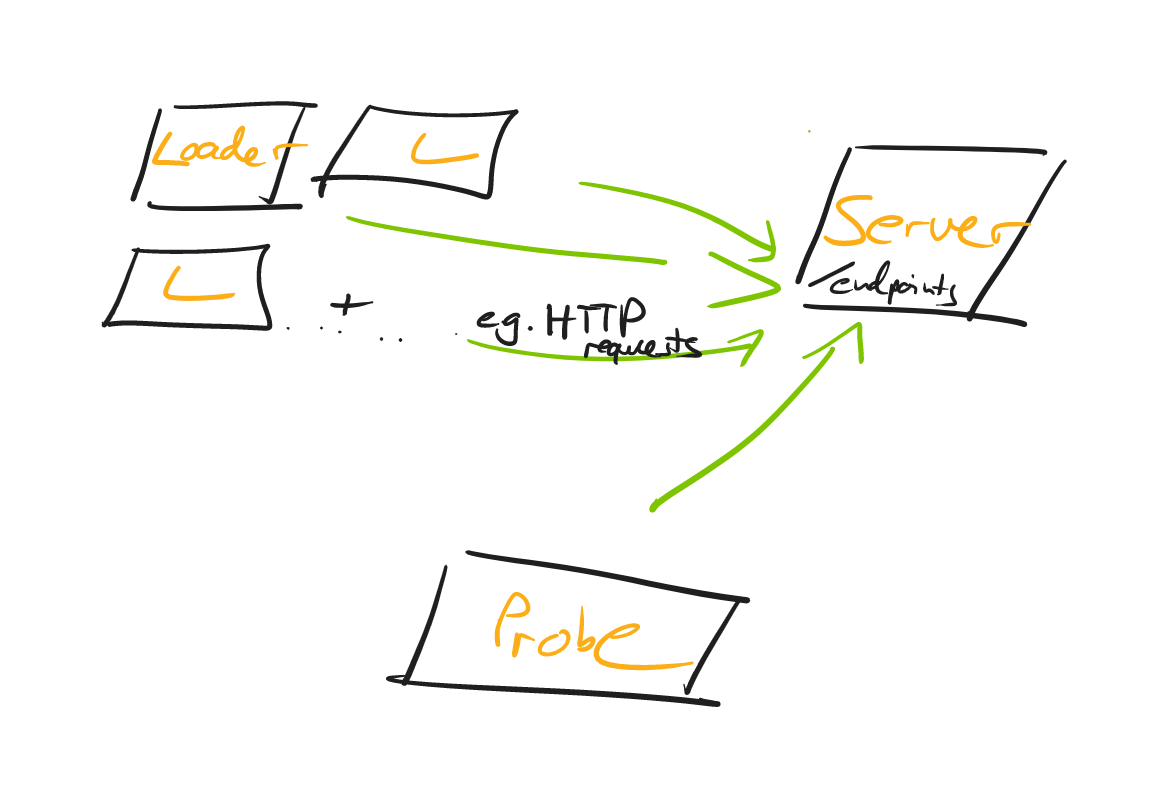
A common shortcut is to generate the load on the same machine (i.e. the
developer’s laptop), that the server is running on. What’s problematic about
that? Generating load needs CPU/Memory/Network Traffic/IO and that will
naturally skew your test results, as to what capacity your server can handle
requests. Hence, you’ll want to introduce the concept of a loader: A loader is
nothing more than a machine that runs e.g. an HTTP Client that fires off
requests against your server. A loader sends n-RPS (requests per second) and,
of course, you’ll be able to adjust the number across test runs. You can start
with a single loader for your load tests, but once that loader struggles to
generate the load, you’ll want to have multiple loaders. (Like 3 in the
graphic above, though there is nothing magical about 3, it could be 2, it
could be 50). It’s also important that the loader generates those requests at
a constant rate, best done asynchronously, so that response processing doesn’t
get in the way of sending out new requests. ... Bonus points if the loaders
aren’t on the same physical machine, i.e. not just adjacent VMs, all sharing
the same underlying hardware.
Open-Source Testing: Why Bug Bounty Programs Should Be Embraced, Not Feared
There are two main challenges: one around decision-making, and another around
integrations. Regarding decision-making, the process can really vary according
to the project. For example, if you are talking about something like Rails,
then there is an accountable group of people who agree on a timetable for
releases and so on. However, within the decentralized ecosystem, these
decisions may be taken by the community. For example, the DeFi protocol
Compound found itself in a situation last year where in order to agree to have
a particular bug fixed, token-holders had to vote to approve the proposal. ...
When it comes to integrations, these often cause problems for testers, even if
their product is not itself open-source. Developers include packages or
modules that are written and maintained by volunteers outside the company,
where there is no SLA in force and no process for claiming compensation if
your application breaks because an open-source third party library has not
been updated, or if your build script pulls in a later version of a package
that is not compatible with the application under test.
3 automation trends happening right now

IT automation specifically continues to grow as a budget priority for CIOs,
according to Red Hat’s 2022 Global Tech Outlook. While it’s outranked as a
discrete spending category by the likes of security, cloud management, and cloud
infrastructure, in reality, automation plays an increasing role in each of those
areas. ... While organizations and individuals automate tasks and processes for
a bunch of different reasons, the common thread is usually this: Automation
either reduces painful (or simply boring) work or it enables capabilities that
would otherwise be practically impossible – or both. “Automation has helped IT
and engineering teams take their processes to the next level and achieve scale
and diversity not possible even a few years ago,” says Anusha Iyer, co-founder
and CTO of Corsha. ... Automation is central to the ability to scale – quickly,
reliably, and securely – distributed systems, whether viewed from an
infrastructure POV (think hybrid cloud and multi-cloud operations), application
architecture POV, security POV, or though virtually any other lens. Automation
is key to making it work.
CIO, CDO and CTO: The 3 Faces of Executive IT

Most companies lack experience with the CDO and CTO positions. This makes these
positions (and those filling them) vulnerable to failure or misunderstanding.
The CIO, who has supervised most of the responsibilities that the CDO and CTO
are being assigned, can help allay fears, and benefit from the cooperation, too.
This can be done by forging a collaborative working partnership with both the
CDO and CTO, which will need IT’s help. By taking a pivotal and leading role in
building these relationships, the CIO reinforces IT’s central role, and helps
the company realize the benefits of executive visibility of the three faces of
IT: data, new technology research, and developing and operating IT business
operations. Many companies opt to place the CTO and CDO in IT, where they report
to the CIO. Sometimes this is done upfront. Other times, it is done when the CEO
realizes that he/she doesn't have the time or expertise to manage three
different IT functions.. This isn't a bad idea since the CIO already understands
the challenges of leveraging data and researching new technologies.
Log4j: The Pain Just Keeps Going and Going

Why is Log4j such a persistent pain in the rump? First, it’s a very popular,
open source Java-based logging framework. So it’s been embedded into thousands
of other software packages. That’s no typo. Log4j is in thousands of programs.
Adding insult to injury, Log4j is often deeply embedded in code and hidden from
view due to being called in by indirect dependencies. So, the CSRB stated that
“Defenders faced a particularly challenging situation; the vulnerability
impacted virtually every networked organization, and the severity of the threat
required fast action.” Making matters worse, according to CSRB, “There is no
comprehensive ‘customer list’ for Log4j or even a list of where it is integrated
as a subsystem.” ... The pace, pressure, and publicity compounded the
defensive challenges: security researchers quickly found additional
vulnerabilities in Log4j, contributing to confusion and ‘patching fatigue’;
defenders struggled to distinguish vulnerability scanning by bona fide
researchers from threat actors, and responders found it difficult to find
authoritative sources of information on how to address the issues,” the CSRB
said.
Major Takeaways: Cyber Operations During Russia-Ukraine War
The operational security expert known as the grugq says Russia did disrupt
command-and-control communications - but the disruption failed to stymie
Ukraine's military. The government had reorganized from a "Soviet-style"
centralized command structure to empower relatively low-level military officers
to make major decisions, such as blowing up runways at strategically important
airports before they were captured by Russian forces. Lack of contact with
higher-ups didn't compromise the ability of Ukraine's military to physically
defend the country. ... Another surprising development is the open involvement
of Western technology companies in Ukraine's cyber defense, WithSecure's
Hypponen says. "I'm surprised by the fact that Western technology companies like
Microsoft and Google are there on the battlefield, supporting Ukraine against
governmental attacks from Russia, which is again, something we've never seen in
any other war." Western corporations aren't alone, either. Kyiv raised a
first-ever volunteer "IT Army," consisting of civilians recruited to break
computer crime laws in aid of the country's military defense.
Quote for the day:
"Leadership is a way of thinking, a way
of acting and, most importantly, a way of communicating." --
Simon Sinek
No comments:
Post a Comment