Ransomware Phishing Emails Sneak Through SEGs
 The original email purported to need support for a “DWG following Supplies
List,” which is supposedly hyperlinked to a Google Drive URL. The URL is
actually an infection link, which downloaded an .MHT file. “.MHT file extensions
are commonly used by web browsers as a webpage archive,” Cofense researchers
explained. “After opening the file the target is presented with a blurred out
and apparently stamped form, but the threat actor is using the .MHT file to
reach out to the malware payload.” That payload comes in the form of a
downloaded .RAR file, which in turn contains an .EXE file. “The executable is a
DotNETLoader that uses VBS scripts to drop and run the MIRCOP ransomware in
memory,” according to the analysis. ... “Its opening lure is business-themed,
making use of a service – such as Google Drive – that enterprises employ for
delivering files,” the researchers explained. “The rapid deployment from the MHT
payload to final encryption shows that this group is not concerned with being
sneaky. Since the delivery of this ransomware is so simple, it is especially
worrying that this email found its way into the inbox of an environment using a
SEG.”
The original email purported to need support for a “DWG following Supplies
List,” which is supposedly hyperlinked to a Google Drive URL. The URL is
actually an infection link, which downloaded an .MHT file. “.MHT file extensions
are commonly used by web browsers as a webpage archive,” Cofense researchers
explained. “After opening the file the target is presented with a blurred out
and apparently stamped form, but the threat actor is using the .MHT file to
reach out to the malware payload.” That payload comes in the form of a
downloaded .RAR file, which in turn contains an .EXE file. “The executable is a
DotNETLoader that uses VBS scripts to drop and run the MIRCOP ransomware in
memory,” according to the analysis. ... “Its opening lure is business-themed,
making use of a service – such as Google Drive – that enterprises employ for
delivering files,” the researchers explained. “The rapid deployment from the MHT
payload to final encryption shows that this group is not concerned with being
sneaky. Since the delivery of this ransomware is so simple, it is especially
worrying that this email found its way into the inbox of an environment using a
SEG.”How Decentralized Finance Will Impact Business Financial Services
In essence, DeFi aims to provide a worldwide, decentralized alternative to every financial service now available, such as insurance, savings, and loans. DeFi’s primary goal is to offer financial services to the world’s 1.7 billion unbanked individuals. And this is possible because DeFi is borderless. These financial services are available to anybody with a smartphone and internet connection in any part of the world. For the impoverished and unbanked, this will revolutionize banking. They can invest anywhere in the world in anything with just the touch of a button. By providing open access for all, DeFi empowers individuals and businesses to maintain greater control over their assets and gives them the financial freedom to select how to invest their money without relying on any intermediary. DeFi is also censorship-resistant, making it immune from government intervention. Furthermore, sending money across borders is extremely costly under the existing system. DeFi eliminates the need for costly intermediaries, allowing for better interest rates and lower expenses, while also democratizing banking systems.Addressing the Low-Code Security Elephant in the Room
 What are some development choices about the application layer that affect the
security responsibility? If the low-code application is strictly made up of
low-code platform native capabilities or services, you only have to worry
about the basics. That includes application design and business logic flaws,
securing your data in transit and at rest, security misconfigurations,
authentication, authorizing and adhering to the principle of least-privilege,
providing security training for your citizen developers, and maintaining a
secure deployment environment. These are the same elements any developer —
low-code or traditional — would need to think about in order to secure the
application. Everything else is handled by the low-code platform itself. That
is as basic as it gets. But what if you are making use of additional widgets,
components, or connectors provided by the low-code platform? Those components
— and the code used to build them — are definitely out of your jurisdiction of
responsibility. You may need to consider how they are configured or used in
your application, though.
What are some development choices about the application layer that affect the
security responsibility? If the low-code application is strictly made up of
low-code platform native capabilities or services, you only have to worry
about the basics. That includes application design and business logic flaws,
securing your data in transit and at rest, security misconfigurations,
authentication, authorizing and adhering to the principle of least-privilege,
providing security training for your citizen developers, and maintaining a
secure deployment environment. These are the same elements any developer —
low-code or traditional — would need to think about in order to secure the
application. Everything else is handled by the low-code platform itself. That
is as basic as it gets. But what if you are making use of additional widgets,
components, or connectors provided by the low-code platform? Those components
— and the code used to build them — are definitely out of your jurisdiction of
responsibility. You may need to consider how they are configured or used in
your application, though.Google Introduces ClusterFuzzLite Security Tool for CI/CD
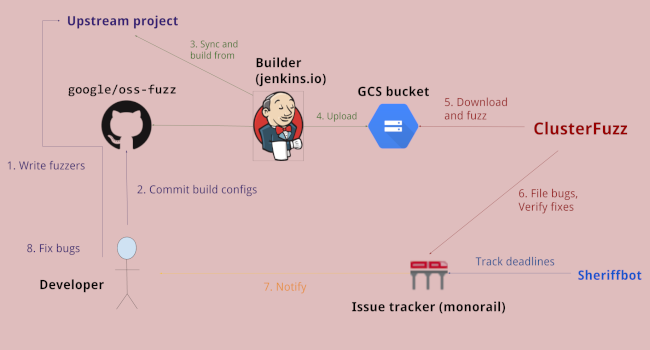 ClusterFuzzLite enables you to run continuous fuzzing on your Continuous
integration and delivery (CI/CD) pipeline. The result? You’ll find
vulnerabilities more easily and faster than ever before. This is vital. A 2020
GitLab DevSecOps survey found that, while 81% of developers believed fuzz
testing is important, only 36% were actually using fuzzing. Why? Because it
was too much trouble to set fuzzing up and integrate it with their CI/CD
systems. At the same time, though, as Shuah Khan, kernel maintainer and the
Linux Foundation’s third Linux Fellow, has pointed out “It is easier to detect
and fix problems during the development process,” than it is to wait for
manual testing or quality assurance later in the game. By feeding unexpected
or random data into a program, fuzzing catches bugs that would otherwise slip
past the most careful eyeballs. NIST’s guidelines for software verification
specify fuzzing as a minimum standard requirement for code verification. After
all as Dan Lorenc, founder and CEO of Chainguard and former Google open source
security team software engineer, recently told The New Stack,
ClusterFuzzLite enables you to run continuous fuzzing on your Continuous
integration and delivery (CI/CD) pipeline. The result? You’ll find
vulnerabilities more easily and faster than ever before. This is vital. A 2020
GitLab DevSecOps survey found that, while 81% of developers believed fuzz
testing is important, only 36% were actually using fuzzing. Why? Because it
was too much trouble to set fuzzing up and integrate it with their CI/CD
systems. At the same time, though, as Shuah Khan, kernel maintainer and the
Linux Foundation’s third Linux Fellow, has pointed out “It is easier to detect
and fix problems during the development process,” than it is to wait for
manual testing or quality assurance later in the game. By feeding unexpected
or random data into a program, fuzzing catches bugs that would otherwise slip
past the most careful eyeballs. NIST’s guidelines for software verification
specify fuzzing as a minimum standard requirement for code verification. After
all as Dan Lorenc, founder and CEO of Chainguard and former Google open source
security team software engineer, recently told The New Stack, Bitcoin Is How We Really Build A New Financial System
 When it comes to a foundational sound money, Bitcoin is unmatched. Compared to
other blockchain assets, Bitcoin has had an immaculate conception.Also,
Bitcoin has an elegantly simple monetary policy and an immutable supply freed
from human discretion – something no other cryptocurrency asset can provide.
Bitcoin's monetary policy is based on algorithmically-determined parameters
and is thus perfectly predictable, rule-based and neither event- nor
emotion-driven. By depoliticizing monetary policy and entrusting money
creation to the market according to rule-based parameters, Bitcoin’s monetary
asset behaves as neutrally as possible. Bitcoin is truly sound money since it
provides the highest degree of stability, reliability and security. Most
crypto enthusiasts would probably object that while Bitcoin might be the
soundest money, its technical capabilities do not allow for DeFi to be built
on top of it. As a matter of fact though, nothing could be further from the
truth.
When it comes to a foundational sound money, Bitcoin is unmatched. Compared to
other blockchain assets, Bitcoin has had an immaculate conception.Also,
Bitcoin has an elegantly simple monetary policy and an immutable supply freed
from human discretion – something no other cryptocurrency asset can provide.
Bitcoin's monetary policy is based on algorithmically-determined parameters
and is thus perfectly predictable, rule-based and neither event- nor
emotion-driven. By depoliticizing monetary policy and entrusting money
creation to the market according to rule-based parameters, Bitcoin’s monetary
asset behaves as neutrally as possible. Bitcoin is truly sound money since it
provides the highest degree of stability, reliability and security. Most
crypto enthusiasts would probably object that while Bitcoin might be the
soundest money, its technical capabilities do not allow for DeFi to be built
on top of it. As a matter of fact though, nothing could be further from the
truth. A Simple 5-Step Framework to Minimize the Risk of a Data Breach
 The first step businesses need to take to increase the security of their
customer data is to review what types of data they're collecting and why. Most
companies that undertake this exercise end up surprised by what they find.
That's because, over time, the volume and variety of customer information that
gets collected to expand well beyond a business's original intent. For
example, it's fairly standard to collect things like a customer's name and
email address. And if that's all a business has on file, they won't be an
attractive target to an attacker. But if the business has a cloud call center
or any type of high touch sales cycle or customer support it probably collects
home addresses, financial data, and demographic information, they've then
assembled a collection that's perfect for enabling identity theft if the data
got out into the wild. So, when evaluating each collected data point to
determine its value, businesses should ask themselves: what critical business
function does this data facilitate. If the answer is none, they should purge
the data and stop collecting it.
The first step businesses need to take to increase the security of their
customer data is to review what types of data they're collecting and why. Most
companies that undertake this exercise end up surprised by what they find.
That's because, over time, the volume and variety of customer information that
gets collected to expand well beyond a business's original intent. For
example, it's fairly standard to collect things like a customer's name and
email address. And if that's all a business has on file, they won't be an
attractive target to an attacker. But if the business has a cloud call center
or any type of high touch sales cycle or customer support it probably collects
home addresses, financial data, and demographic information, they've then
assembled a collection that's perfect for enabling identity theft if the data
got out into the wild. So, when evaluating each collected data point to
determine its value, businesses should ask themselves: what critical business
function does this data facilitate. If the answer is none, they should purge
the data and stop collecting it. To Monitor or Not to Monitor a Model — Is there a question?
IBM’s latest quantum chip breaks the elusive 100-qubit barrier
 The Eagle is a quantum processor that is around the size of a quarter. Unlike
regular computer chips, which encode information as 0 or 1 bits, quantum
computers can represent information in something called qubits, which can have
a value of 0, 1, or both at the same time due to a unique property called
superposition. By holding over 100 qubits in a single chip, IBM says that
Eagle could increase the “memory space required to execute algorithms,” which
would in theory help quantum computers take on more complex problems. “People
have been excited about the prospects of quantum computers for many decades
because we have understood that there are algorithms or procedures you can run
on these machines that you can’t run on conventional or classical computers,”
says David Gosset, an associate professor at the University of Waterloo’s
Institute for Quantum Computing who works on research with IBM, “which can
accelerate the solution of certain, specific problems.”
The Eagle is a quantum processor that is around the size of a quarter. Unlike
regular computer chips, which encode information as 0 or 1 bits, quantum
computers can represent information in something called qubits, which can have
a value of 0, 1, or both at the same time due to a unique property called
superposition. By holding over 100 qubits in a single chip, IBM says that
Eagle could increase the “memory space required to execute algorithms,” which
would in theory help quantum computers take on more complex problems. “People
have been excited about the prospects of quantum computers for many decades
because we have understood that there are algorithms or procedures you can run
on these machines that you can’t run on conventional or classical computers,”
says David Gosset, an associate professor at the University of Waterloo’s
Institute for Quantum Computing who works on research with IBM, “which can
accelerate the solution of certain, specific problems.”
Industrial computer vision is getting ready for growth
 Industrial applications, however, present some unique challenges for computer
vision systems. Many organizations can’t use pretrained machine learning
models that have been tuned to publicly available data. They need models that
are trained on their specific data. Sometimes, those organizations don’t have
enough data to train their ML models from scratch, so they need to go through
some more complicated processes, such as pretraining the model on a general
dataset and then finetuning it on their own labeled images. The challenges of
industrial computer vision are not limited to data. Sometimes, sensitivities
such as safety or transparency impose special requirements on the type of
algorithm and accuracy metrics used in industrial computer vision systems. And
the team running the model needs an entire MLOps stack to monitor model
performance, iterate across models, maintain different versions of the models,
and manage a pipeline for gathering new data and retraining the models.
Industrial applications, however, present some unique challenges for computer
vision systems. Many organizations can’t use pretrained machine learning
models that have been tuned to publicly available data. They need models that
are trained on their specific data. Sometimes, those organizations don’t have
enough data to train their ML models from scratch, so they need to go through
some more complicated processes, such as pretraining the model on a general
dataset and then finetuning it on their own labeled images. The challenges of
industrial computer vision are not limited to data. Sometimes, sensitivities
such as safety or transparency impose special requirements on the type of
algorithm and accuracy metrics used in industrial computer vision systems. And
the team running the model needs an entire MLOps stack to monitor model
performance, iterate across models, maintain different versions of the models,
and manage a pipeline for gathering new data and retraining the models.Three Big Myths About Decentralized Finance
Because the blockchain uses so many distinct sources to verify and record what happens within the system, there is also a common misconception that decentralized finance is inherently safer than centralized systems run by a single financial institution. After all, if thousands of sources check my transactions, won't they be able to identify and prevent anyone trying to use my account without my permission? Not necessarily. While it's true that the blockchain does help to safeguard against administrative or accounting errors — as happened recently with one family who mistakenly received $50 billion in their account — it also removes the safeguards that centralized financial businesses provide. Most of today's largest financial institutions have been around for decades. Over the years, federal and industry regulation have been put in place to provide safeguards against fraud. Navigating these safeguards can no doubt be tiresome, but they do provide valuable protections.Quote for the day:
"A leadership disposition guides you to take the path of most resistance and turn it into the path of least resistance." -- Dov Seidman
No comments:
Post a Comment