Understanding Supervised, Unsupervised, and Reinforcement Learning

With supervised learning, you feed the output of your algorithm into the system. This means that in supervised learning, the machine already knows the output of the algorithm before it starts working on it or learning it. A basic example of this concept would be a student learning a course from an instructor. The student knows what he/she is learning from the course. With the output of the algorithm known, all that a system needs to do is to work out the steps or process needed to reach from the input to the output. The algorithm is being taught through a training data set that guides the machine. If the process goes haywire and the algorithms come up with results completely different than what should be expected, then the training data does its part to guide the algorithm back towards the right path. Supervised Machine Learning currently makes up most of the ML that is being used by systems across the world. The input variable (x) is used to connect with the output variable (y) through the use of an algorithm.
Shift your Java applications into containers with Jelastic PaaS
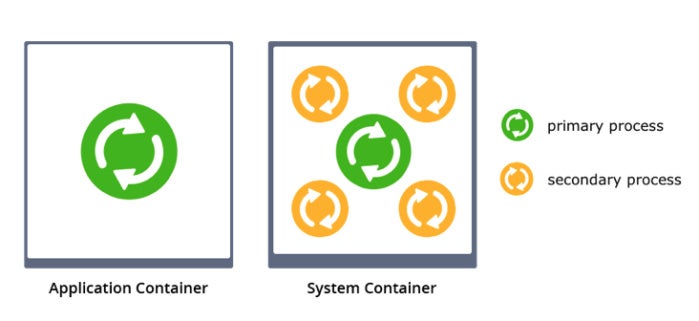
System containers offer multiple benefits when migrating an existing legacy application. IP addresses, hostnames, and locally stored data can survive container downtimes, there’s no need for port mapping, and you gain a far better isolation and virtualization of resources. Plus you get compatibility with SSH-based config tools and even hibernation and live migration of the memory state. The only perceptible disadvantage compared to application containers might be a slower start-up time as system containers are a bit heavier due to the additional services required for running multiple processes. In Jelastic, it is possible to run both application and system containers. In contrast to other PaaS vendors that use the so-called Twelve-Factor App methodology, Jelastic does not force customers to use any specific approach or application design in order to deploy cloud-native microservices and legacy monoliths.
How machine learning can be used to write more secure computer programs
By transforming software code into a graph, you can actually extract different properties from that code by analyzing the graph. ... Let’s take a smaller function that might have one IF block. One of the graph structures that’s first generated is called an abstract syntax tree. That’s a tree that you’d get by just parsing the code. ... For each IF and for each variable, for each statement, there’s going to be a node. For each operator, like if there’s an assignment, there’s also going to be a node, and they are all connected by edges. You soon run into a lot of nodes and edges. If you take something like, let’s say, the Linux kernel, you’ll have several hundreds of thousands of nodes. ... You can do a lot by essentially solving reachability problems in these graphs.
Cheap Raspberry Pi alternatives: 20 computers that cost less than the Pi 3

On its release in 2012, the $35 Raspberry Pi showed just how much computer you could get for a bargain-basement price. But the cost of single-board computers has just kept dropping, with the Raspberry Pi Foundation releasing the tiny Pi Zero for just $5. Today the Zero is one of several computers with a single-digit price tag, and if you're looking for an as cheap as chips board you're spoiled for choice. These are the single-board computers that you can pick up for less than a price of the $35 Pi. One thing to bear in mind is that the cheapest offerings lack many of the features of the Raspberry Pi 3 Model B, and have more in common with the $5/$10 Raspberry Pi Zero. Even the more expensive boards are at somewhat of a disadvantage compared to the Pi range, lacking their breadth of stable software, tutorials and community support.
Server vendors push flex pricing to challenge cloud providers

For many customers who are just starting to use cloud services, these plans offer a means for making a graceful transition. “Customers want the flexibility to start with a certain capacity and scale as needed,” he said. The success of public cloud services is forcing the hand of vendors to compete by addressing some of the shortcomings of cloud. “Our advice back to these vendors is the time is right because more and more companies are putting more workloads on public cloud that require more storage,” said Stanley Stevens, an analyst with Technology Business Research Companies. “They are getting sticker shock because when they replicated their environment in the public cloud, they realized a lot of that storage is inefficient and unused.” The real cost of the cloud is not the workload, but moving around data, he said. Cloud providers like Amazon and Microsoft charge you for data sent up to their data center, storage, processing, and data sent back down to you.
IT sabotage: Identifying and preventing insider threats

Insiders that commit IT sabotage are technically competent users who have the access and ability to carry out an attack, as well as the capability to conceal their illicit activities. These characteristics make detecting these kinds of insider IT sabotage very difficult, as malicious behavior rarely looks any different than normal behavior. ... However, in nearly every IT insider sabotage attack, distinct patterns have been discovered, and the detection of these patterns can help identify malicious insider activities. The CERT Insider Threat Center has been working for more than 15 years cataloging, analyzing and detecting patterns of malicious insider behavior in order to understand who commits insider attacks, why they do it, when and where they do it, and how they carry out their attacks.
Next-gen Mirai botnet targets cryptocurrency mining operations

Satori.Coin.Robber works “primarily on the Claymore Mining equipment that allows management actions on 3333 ports with no password authentication enabled (which is the default config),” the researchers said. “To prevent potential abuse, we will not discuss details.” Analysis of the botnet code revealed similarities with the original Satori, including similar code structures, encrypted configurations, similar configuration strings, and the same payload. However, the new variant also comes with a payload targeting the Claymore Miner that features an asynchronous network connection method and enables a new set of command and control communication protocols. Researchers noted that the author behind Satori.Coin.Robber has claimed the code is not malicious, and has even left an email address behind.
Convolutional neural networks for language tasks
Notice how the CNN processes the input as a complete sentence, rather than word by word as we did with the LSTM. For our CNN, we pass a tensor with all word indices in our sentence to our embedding lookup and get back the matrix for our sentence that will be used as the input to our network. Now that we have our embedded representation of our input sentence, we build our convolutional layers. In our CNN, we will use one-dimensional convolutions, as opposed to the two-dimensional convolutions typically used on vision tasks. Instead of defining a height and a width for our filters, we will only define a height, and the width will always be the embedding dimension. This makes sense intuitively, when compared to how images are represented in CNNs. When we deal with images, each pixel is a unit for analysis, and these pixels exist in both dimensions of our input image.
Configuration errors in Intel workstations being labeled a security hole

Normally computers with AMT have a BIOS password to prevent making low-level changes, but due to insecure defaults in the BIOS and AMT’s BIOS extension (MEBx) configuration, an attacker with physical access can log in using the default password “admin.” Given the bad security habits of many people, there’s a good chance this default password was not changed. By changing the default password, enabling remote access and setting AMT’s user opt-in to “None,” the attacker has now backdoored the machine and can gain access to the system remotely, assuming the attacker is on the same network as the target machine. Intel says this is a problem in how the machine is configured by the OEM. Its recommendation is that MEBx access be gated by the BIOS password and has said so since 2015. What F-Secure found is that some system manufacturers were not requiring a BIOS password to access MEBx. So it updated its guidance for proper AMT/MEBx security in December.
The role of the data curator: Make data scientists more productive
The data curator has a good understanding of the types of systems that store the data, and the types of tools that can be used for processing the data, even if they are not practitioners of these technologies themselves. They have up-to-date knowledge about datasets, their provenance, and what data curation is needed. They also understand the different types of analysis that need to be performed on specific datasets, as well as the expectations in terms of latency and availability set by diverse business users. By working with data engineers, data custodians, data analysts, and data scientists, the data curator develops a deep understanding of how data is used by the business, and how IT applies technology to make the data available. Data curators are making data analysts and data scientists more productive by allowing them to focus on what they do best.
Quote for the day:
"It is impossible to defeat an ignorant man in an argument." -- William G. Mcadoo
No comments:
Post a Comment