Quote for the day:
"Winners are not afraid of losing. But losers are. Failure is part of the process of success. People who avoid failure also avoid success." -- Robert T. Kiyosaki
🎧 Listen to this digest on YouTube Music
▶ Play Audio DigestDuration: 25 mins • Perfect for listening on the go.
Shadow agents: How IT leaders must govern ‘headless’ AI before it breaks the enterprise
 As businesses increasingly rely on autonomous artificial intelligence to
handle complex tasks, technology leaders are facing a new security challenge.
Invisible AI programs are operating in the background of enterprise networks,
completing workflows without logging in or leaving standard audit trails.
Driven by the high costs of cloud computing, organizations are shifting these
automated tools to run locally on employee laptops. Because conventional
security systems are designed to monitor human behavior, they cannot track
these automated processes, leaving teams blind to what the software is
accessing or deciding. To safely manage this shift, companies need to move
away from traditional perimeter defenses and adopt strict containment
strategies. By placing these programs in isolated environments, organizations
can strictly control their permissions and limit their access to sensitive
information. This transition also requires dedicated engineers focused on
establishing behavioral rules, testing instructions, and securing data
retrieval. Governing these automated systems at scale demands centralized
oversight and clear policies. By establishing this accountability
infrastructure now, technology leaders can confidently harness the power of
autonomous software without compromising their security or losing visibility
into their own networks.
As businesses increasingly rely on autonomous artificial intelligence to
handle complex tasks, technology leaders are facing a new security challenge.
Invisible AI programs are operating in the background of enterprise networks,
completing workflows without logging in or leaving standard audit trails.
Driven by the high costs of cloud computing, organizations are shifting these
automated tools to run locally on employee laptops. Because conventional
security systems are designed to monitor human behavior, they cannot track
these automated processes, leaving teams blind to what the software is
accessing or deciding. To safely manage this shift, companies need to move
away from traditional perimeter defenses and adopt strict containment
strategies. By placing these programs in isolated environments, organizations
can strictly control their permissions and limit their access to sensitive
information. This transition also requires dedicated engineers focused on
establishing behavioral rules, testing instructions, and securing data
retrieval. Governing these automated systems at scale demands centralized
oversight and clear policies. By establishing this accountability
infrastructure now, technology leaders can confidently harness the power of
autonomous software without compromising their security or losing visibility
into their own networks.The 20 Software Engineering Laws
The DZone article "The 20 Software Engineering Laws" by Dr. Milan Milanovic
explores fundamental principles that dictate how software projects actually
unfold, rather than how we hope they will. Instead of focusing on code syntax,
these laws address the human, organizational, and structural realities that
engineers face when working under pressure. The piece categorizes these
principles into several practical themes, such as system building, speed,
planning, and metrics. For instance, laws related to system building include
Conway’s Law, which states that a system’s architecture inevitably mirrors a
company's communication structure, and Gall’s Law, reminding us that
successful complex systems must evolve from working simple ones. When
exploring lost speed, the author highlights Brooks’s Law, explaining why
adding more developers to a late project only delays it further. The article
also tackles planning and metrics, citing Parkinson's Law, where work expands
to fill available time, and Goodhart's Law, which warns that when a measure
becomes a target, it stops being a good measure. By grounding these concepts
in real-world examples like Instagram's pivot and Berlin's delayed airport,
the article provides a practical framework to help engineers navigate common
pitfalls with confidence and clarity.
Machine Unlearning with Minimal Gradient Dependence for High Unlearning Ratios
 As machine learning systems process enormous volumes of information, the
ability to make them forget specific private data is increasingly critical for
security. A recent research paper introduces Mini-Unlearning, a method
designed to tackle the difficulties of removing information when a large
proportion of the original data must be forgotten. Traditional approaches to
this problem usually require saving extensive records of past training
updates, which demands heavy memory usage and becomes inefficient at scale. To
resolve this, Mini-Unlearning operates on the mathematical insight that
unlearned settings naturally correspond to retrained settings through a
predictable geometric relationship. By taking advantage of this relationship,
the new technique effectively calculates necessary adjustments using only a
tiny subset of recent training updates. This approach completely bypasses the
need for full historical records, greatly lowering the required computational
power and memory. Testing shows that this lightweight method successfully
deletes targeted personal information while maintaining overall system
accuracy and effectively defending against targeted attempts to uncover hidden
user data. Ultimately, this scalable solution allows organizations to reliably
comply with strict privacy regulations without compromising the performance or
efficiency of their broader systems.
As machine learning systems process enormous volumes of information, the
ability to make them forget specific private data is increasingly critical for
security. A recent research paper introduces Mini-Unlearning, a method
designed to tackle the difficulties of removing information when a large
proportion of the original data must be forgotten. Traditional approaches to
this problem usually require saving extensive records of past training
updates, which demands heavy memory usage and becomes inefficient at scale. To
resolve this, Mini-Unlearning operates on the mathematical insight that
unlearned settings naturally correspond to retrained settings through a
predictable geometric relationship. By taking advantage of this relationship,
the new technique effectively calculates necessary adjustments using only a
tiny subset of recent training updates. This approach completely bypasses the
need for full historical records, greatly lowering the required computational
power and memory. Testing shows that this lightweight method successfully
deletes targeted personal information while maintaining overall system
accuracy and effectively defending against targeted attempts to uncover hidden
user data. Ultimately, this scalable solution allows organizations to reliably
comply with strict privacy regulations without compromising the performance or
efficiency of their broader systems.Reliability Comes From the System, Not the Agent
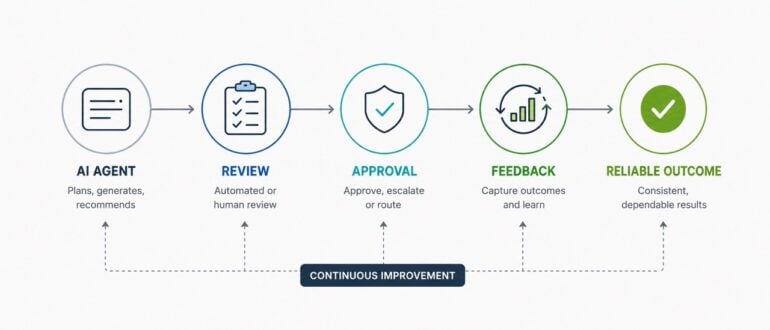 When adopting artificial intelligence, many executives mistakenly judge an AI
agent’s reliability in complete isolation. This perspective stems from
traditional software development practices, where individual components are
expected to function perfectly on their own. However, in complex or
high-stakes environments—such as aviation or healthcare—reliability has never
depended on the perfection of a single actor. Instead, it naturally emerges
from a well-designed surrounding system that anticipates and catches
inevitable human errors before they can escalate into a larger issue. The
exact same principle applies directly to artificial intelligence agents.
Rather than waiting around for a completely flawless model, organizations
should focus their efforts on building robust workflows around these tools. A
truly dependable system assumes occasional failures and uses practical
safeguards like approval gates, continuous feedback loops, and risk-based
reviews to ensure consistent outcomes. When an agent produces an error, it is
not necessarily a sign that the technology is unready; rather, it highlights
the pressing need for stronger operational structures. Ultimately, the
competitive advantage in AI will not come from choosing the best model, but
from designing resilient organizational workflows that gracefully handle
imperfections and deliver predictable results over time.
When adopting artificial intelligence, many executives mistakenly judge an AI
agent’s reliability in complete isolation. This perspective stems from
traditional software development practices, where individual components are
expected to function perfectly on their own. However, in complex or
high-stakes environments—such as aviation or healthcare—reliability has never
depended on the perfection of a single actor. Instead, it naturally emerges
from a well-designed surrounding system that anticipates and catches
inevitable human errors before they can escalate into a larger issue. The
exact same principle applies directly to artificial intelligence agents.
Rather than waiting around for a completely flawless model, organizations
should focus their efforts on building robust workflows around these tools. A
truly dependable system assumes occasional failures and uses practical
safeguards like approval gates, continuous feedback loops, and risk-based
reviews to ensure consistent outcomes. When an agent produces an error, it is
not necessarily a sign that the technology is unready; rather, it highlights
the pressing need for stronger operational structures. Ultimately, the
competitive advantage in AI will not come from choosing the best model, but
from designing resilient organizational workflows that gracefully handle
imperfections and deliver predictable results over time.Detection engineering: A programmatic approach to identifying cyber threats
 Detection engineering is rapidly becoming a key focus for cybersecurity teams
as organizations look to defend against increasingly advanced digital threats.
Instead of relying heavily on rigid, pre-built rules that often fail to catch
modern attacks, detection engineering takes a highly tailored approach. It
involves building customized systems designed to spot suspicious behaviors
specific to an organization’s unique environment, effectively minimizing the
flood of false alarms that commonly overwhelm security teams today. The
growing interest in this practice is driven by the realization that
traditional, signature-based security methods are no longer sufficient to stop
modern tactics like fileless malware or complex attacks on cloud
infrastructure. By carefully mapping out potential attack paths and analyzing
real-world adversary behavior, companies can proactively spot threats rather
than just reacting after a damaging incident has occurred. Recent surveys
indicate that the vast majority of large enterprises are heavily investing in
these active strategies, with many now establishing dedicated detection teams.
Additionally, artificial intelligence and automation are playing crucial roles
in helping these professionals fine-tune rules and process vast amounts of
threat data. Ultimately, adopting detection engineering reduces the time
attackers can hide within a network, greatly improving an organization's
overall cyber resilience.
Detection engineering is rapidly becoming a key focus for cybersecurity teams
as organizations look to defend against increasingly advanced digital threats.
Instead of relying heavily on rigid, pre-built rules that often fail to catch
modern attacks, detection engineering takes a highly tailored approach. It
involves building customized systems designed to spot suspicious behaviors
specific to an organization’s unique environment, effectively minimizing the
flood of false alarms that commonly overwhelm security teams today. The
growing interest in this practice is driven by the realization that
traditional, signature-based security methods are no longer sufficient to stop
modern tactics like fileless malware or complex attacks on cloud
infrastructure. By carefully mapping out potential attack paths and analyzing
real-world adversary behavior, companies can proactively spot threats rather
than just reacting after a damaging incident has occurred. Recent surveys
indicate that the vast majority of large enterprises are heavily investing in
these active strategies, with many now establishing dedicated detection teams.
Additionally, artificial intelligence and automation are playing crucial roles
in helping these professionals fine-tune rules and process vast amounts of
threat data. Ultimately, adopting detection engineering reduces the time
attackers can hide within a network, greatly improving an organization's
overall cyber resilience.Compute Concentration: The Emerging Enterprise Risk Inside the AI Economy
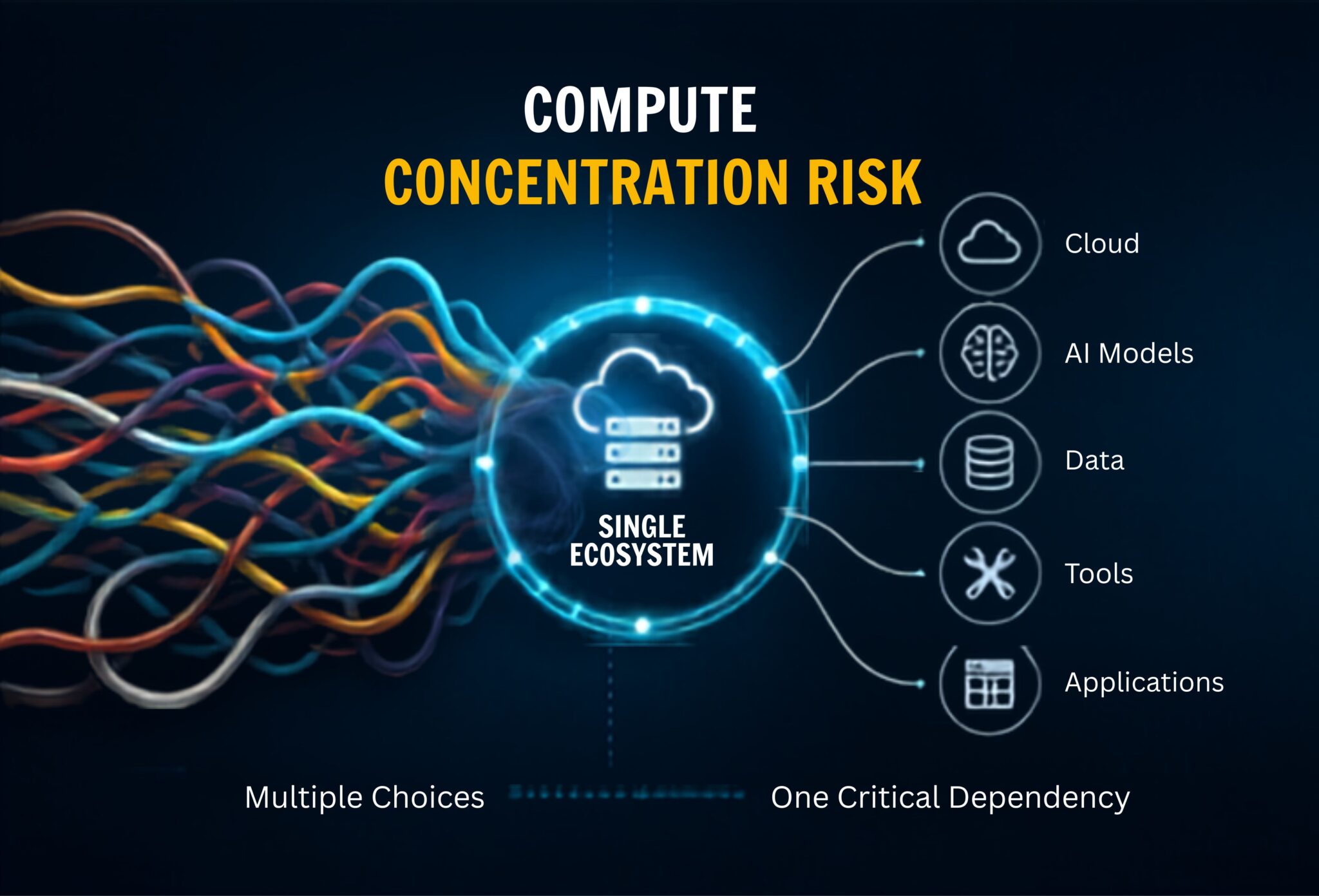 As artificial intelligence transitions from testing to full-scale operations,
a new, hidden challenge is emerging for modern businesses: compute
concentration. This happens when companies quietly become overly reliant on a
very small group of external providers for the core infrastructure needed to
run their systems, such as cloud storage, data centers, and computer chips.
Often, this dependency develops by accident. A company might start with one
provider for ease of use and speed, eventually deeply intertwining all their
critical functions within a single technology ecosystem. While working with
large providers offers undeniable benefits like strong security and massive
scale, heavy reliance creates significant vulnerabilities. If a primary
provider experiences an outage, changes their pricing, or alters their
policies, the affected business faces immediate disruptions, unexpected costs,
and a loss of control over their own operations. It is not just about managing
vendors; it is a fundamental issue of business continuity and strategic
independence. True resilience does not mean avoiding large providers entirely,
but rather fully understanding these deep dependencies. Organizations must
ensure they have viable alternatives ready so they are not caught off guard if
their primary technology foundation shifts.
As artificial intelligence transitions from testing to full-scale operations,
a new, hidden challenge is emerging for modern businesses: compute
concentration. This happens when companies quietly become overly reliant on a
very small group of external providers for the core infrastructure needed to
run their systems, such as cloud storage, data centers, and computer chips.
Often, this dependency develops by accident. A company might start with one
provider for ease of use and speed, eventually deeply intertwining all their
critical functions within a single technology ecosystem. While working with
large providers offers undeniable benefits like strong security and massive
scale, heavy reliance creates significant vulnerabilities. If a primary
provider experiences an outage, changes their pricing, or alters their
policies, the affected business faces immediate disruptions, unexpected costs,
and a loss of control over their own operations. It is not just about managing
vendors; it is a fundamental issue of business continuity and strategic
independence. True resilience does not mean avoiding large providers entirely,
but rather fully understanding these deep dependencies. Organizations must
ensure they have viable alternatives ready so they are not caught off guard if
their primary technology foundation shifts.Preventing agent-generated infrastructure bloat through spec-driven governance
 Autonomous AI engineering agents can drastically improve software delivery
speed, but they also risk creating massive infrastructure bloat if left
unchecked. Because these agents often default to the inefficient patterns
found in their training data, they frequently over-provision resources—such as
requesting excessively large Kubernetes pods or pulling bloated container
images. This inefficiency replicates rapidly across environments, wasting
cloud space and increasing energy consumption. To prevent this, organizations
must implement strict, spec-driven governance directly within their
development pipelines. Instead of treating sustainability and efficiency as
afterthoughts, engineering teams need to embed clear constraints into their
infrastructure specifications. By defining rules for machine types, pod
resource limits, and minimal base images before the agent generates any code,
the agent is forced to execute within those boundaries. Organizations can
enforce these constraints using static analysis tools and quality gates that
block non-compliant deployments. Addressing this issue upstream ensures that
agent-driven development yields efficient, cost-effective, and sustainable
infrastructure by design, rather than creating a sprawling operational mess
that becomes nearly impossible to fix later.
Autonomous AI engineering agents can drastically improve software delivery
speed, but they also risk creating massive infrastructure bloat if left
unchecked. Because these agents often default to the inefficient patterns
found in their training data, they frequently over-provision resources—such as
requesting excessively large Kubernetes pods or pulling bloated container
images. This inefficiency replicates rapidly across environments, wasting
cloud space and increasing energy consumption. To prevent this, organizations
must implement strict, spec-driven governance directly within their
development pipelines. Instead of treating sustainability and efficiency as
afterthoughts, engineering teams need to embed clear constraints into their
infrastructure specifications. By defining rules for machine types, pod
resource limits, and minimal base images before the agent generates any code,
the agent is forced to execute within those boundaries. Organizations can
enforce these constraints using static analysis tools and quality gates that
block non-compliant deployments. Addressing this issue upstream ensures that
agent-driven development yields efficient, cost-effective, and sustainable
infrastructure by design, rather than creating a sprawling operational mess
that becomes nearly impossible to fix later.Agentic AI creates enterprise challenge beyond LLM boom
As businesses move beyond early experiments with artificial intelligence, they
face a practical new challenge: managing and governing the automated software
programs, or agents, that will soon work alongside human employees. While
recent attention has focused on language models, the conversation is shifting
toward the infrastructure needed to support these agents. Companies must
figure out how to integrate them, control their access to company data, and
manage the costs associated with running them. A primary issue is matching the
right level of computing power to specific tasks to keep expenses predictable
and responses consistent. Because current technology frameworks were built for
human users, new standards are emerging to help these agents communicate
securely with existing systems. Over time, managing the lifecycle of these
digital assistants will become essential to prevent the lack of oversight that
accompanied early cloud software adoption. As regulations develop unevenly
across different regions, leaders are currently focused on learning how to
build the right foundations. Soon, companies will shift from planning to
execution, preparing for a future where each employee might collaborate with
several automated assistants daily, requiring careful oversight and clear
guidelines.
 Digital identity systems are evolving beyond traditional passwords and basic
biometrics by incorporating emotion as a new trust signal. Voice artificial
intelligence is now being trained to analyze vocal cues—such as tone and
pacing—to determine a speaker's underlying emotional state. By converting
these real-time observations into structured data, companies hope to better
understand customer intent, improve service routing, and identify potential
signs of fraud or distress during live interactions. While this technology
aims to close the gap between what people say and what they actually mean, it
introduces significant privacy and ethical concerns. Inferring human emotion
is inherently complex and can easily lead to bias or inaccurate risk profiling
if used improperly. Consequently, industry experts caution that emotional data
should merely provide helpful context rather than serve as definitive proof of
identity or deception. As the market for this technology grows, organizations
must implement it responsibly. This means ensuring clear user consent,
strictly limiting data retention, and mandating human oversight so that
unverified emotional inferences do not independently drive critical decisions
regarding a person's access, credit, or employment.
Digital identity systems are evolving beyond traditional passwords and basic
biometrics by incorporating emotion as a new trust signal. Voice artificial
intelligence is now being trained to analyze vocal cues—such as tone and
pacing—to determine a speaker's underlying emotional state. By converting
these real-time observations into structured data, companies hope to better
understand customer intent, improve service routing, and identify potential
signs of fraud or distress during live interactions. While this technology
aims to close the gap between what people say and what they actually mean, it
introduces significant privacy and ethical concerns. Inferring human emotion
is inherently complex and can easily lead to bias or inaccurate risk profiling
if used improperly. Consequently, industry experts caution that emotional data
should merely provide helpful context rather than serve as definitive proof of
identity or deception. As the market for this technology grows, organizations
must implement it responsibly. This means ensuring clear user consent,
strictly limiting data retention, and mandating human oversight so that
unverified emotional inferences do not independently drive critical decisions
regarding a person's access, credit, or employment.
The rise of emotion as a trust signal
Digital identity systems are evolving beyond traditional passwords and basic
biometrics by incorporating emotion as a new trust signal. Voice artificial
intelligence is now being trained to analyze vocal cues—such as tone and
pacing—to determine a speaker's underlying emotional state. By converting
these real-time observations into structured data, companies hope to better
understand customer intent, improve service routing, and identify potential
signs of fraud or distress during live interactions. While this technology
aims to close the gap between what people say and what they actually mean, it
introduces significant privacy and ethical concerns. Inferring human emotion
is inherently complex and can easily lead to bias or inaccurate risk profiling
if used improperly. Consequently, industry experts caution that emotional data
should merely provide helpful context rather than serve as definitive proof of
identity or deception. As the market for this technology grows, organizations
must implement it responsibly. This means ensuring clear user consent,
strictly limiting data retention, and mandating human oversight so that
unverified emotional inferences do not independently drive critical decisions
regarding a person's access, credit, or employment.The endpoint recovery gap many teams discover during an incident
Organizations often make a costly mistake by assuming that having data backups
is the same as having a comprehensive recovery plan. According to Matthias
Haas, CTO of IGEL, backups are essential for restoring information and
applications, but they do not automatically grant users safe access back into
their work environments. When a significant incident occurs and knocks
thousands of devices offline, companies frequently realize they have planned
for infrastructure recovery while completely ignoring endpoint recovery. This
gap leads to enormous expenses tied to replacing hardware, reimaging devices,
and coordinating manual repairs. A well-planned architecture must focus on
restoring both the systems themselves and the trusted access to those systems.
Rather than relying on technical heroics to fix thousands of individual
devices during a crisis, businesses need pre-planned alternative paths, such
as dual-boot options or secure browser resources. The true measure of
resilience is not the number of threats a security team blocks, but the time
it takes to safely restore trusted user access. By calculating the actual
per-hour cost of interrupted workflows, security leaders can successfully
justify investing in solid endpoint recovery before an incident even
happens.




/articles/rdla-offline-first-reactive-android-data-layer/en/smallimage/rdla-offline-first-reactive-android-data-layer-thumbnail-1781776366032.jpg)






/articles/understanding-ml-model-poisoning/en/smallimage/thumbnail-understanding-ml-model-poisoning-1781597719188.jpg)