Quote for the day:
"When you want to succeed as bad as you want to breathe, then you’ll be successful." -- Eric Thomas
🎧 Listen to this digest on YouTube Music
▶ Play Audio DigestDuration: 18 mins • Perfect for listening on the go.
‘Botsitting’: The AI time-savings killer only governance can stop
 While artificial intelligence promises to free up employees for valuable tasks,
a recent study reveals that workers lose more than half their saved time to
“botsitting.” Digital workers save roughly eleven hours a week using these
tools, but spend over six hours managing them—providing missing context,
checking outputs, fixing mistakes, rewriting prompts, and correcting inaccurate
answers. As a result, businesses are missing out on the full return on their
investments. A core issue is poor governance and a lack of training. Employees
often use AI for simple tasks like drafting emails, distrusting it for complex
work. Moreover, there is “coordination neglect,” where an individual’s
productivity gains create unexpected work for others downstream. For instance,
when workers pass along unchecked, AI-generated content, teammates must spend
unbudgeted time cleaning up the mess. Experts warn that simply implementing
tools without clear guidelines on verification processes and data context leads
to inefficiency. To truly benefit from these technologies, organizations must
focus on proper deployment, establish clear oversight, and define quality
standards rather than merely counting how often tools are used. Reliable
outcomes require thoughtful management, not just fast adoption.
While artificial intelligence promises to free up employees for valuable tasks,
a recent study reveals that workers lose more than half their saved time to
“botsitting.” Digital workers save roughly eleven hours a week using these
tools, but spend over six hours managing them—providing missing context,
checking outputs, fixing mistakes, rewriting prompts, and correcting inaccurate
answers. As a result, businesses are missing out on the full return on their
investments. A core issue is poor governance and a lack of training. Employees
often use AI for simple tasks like drafting emails, distrusting it for complex
work. Moreover, there is “coordination neglect,” where an individual’s
productivity gains create unexpected work for others downstream. For instance,
when workers pass along unchecked, AI-generated content, teammates must spend
unbudgeted time cleaning up the mess. Experts warn that simply implementing
tools without clear guidelines on verification processes and data context leads
to inefficiency. To truly benefit from these technologies, organizations must
focus on proper deployment, establish clear oversight, and define quality
standards rather than merely counting how often tools are used. Reliable
outcomes require thoughtful management, not just fast adoption.The database that refused to die: How Postgres survived its own creators
Postgres, one of the world's most widely used database systems, began its life
with an uncertain future. Created by database pioneer Michael Stonebraker in
the 1980s as a successor to Ingres, the project was essentially abandoned by
its creator in the mid-1990s. Instead of fading into obscurity, Postgres was
rescued by a dedicated community of independent open-source volunteers. These
contributors preserved Stonebraker's foundational, highly adaptable
architecture—which allowed for complex, user-defined data types rather than
just basic strings and numbers—while adding standard SQL capabilities. Today,
this collaborative rescue effort has established Postgres as a cornerstone of
modern cloud computing infrastructure. Its enduring success stems from its
foundational design philosophy. While proprietary database systems
traditionally optimize their software to suit the specific needs of massive
enterprise clients, Postgres was built to handle the diverse workloads of
general users. By seamlessly accommodating complex data formats like
geographic information and computer-aided design files, it solved real-world
problems for a broad audience. Ultimately, the survival and widespread
adoption of Postgres demonstrate the power of open-source software, proving
that community-driven development can outlast even the original creators to
become a resilient industry standard.
Why private AI is the smarter bet
 Although many businesses initially assumed artificial intelligence would
naturally live in the public cloud, reality is forcing a shift toward private,
on-premises systems. According to the article, this transition stems from
growing concerns about uncontrolled costs, security vulnerabilities, and
operational fit. As companies move from small experiments to organization-wide
implementation, the pay-per-token pricing models of public cloud providers
risk becoming massive utility bills that wipe out business gains.
Consequently, the future of enterprise AI leans toward a hybrid model. Rather
than relying entirely on giant public models, businesses are discovering that
smaller, specialized AI models can handle tasks better while running closely
to their own private data. This approach offers better control over
predictable workloads and eliminates surprise expenses. Furthermore, keeping
AI in-house strengthens security and data governance. Using public AI tools
raises the real danger of employees inadvertently exposing sensitive or
proprietary information. While building and managing private AI networks
requires significant investment, skill, and discipline, the long-term benefits
of controlled costs, tight security, and owned infrastructure make it a much
smarter choice for major production workloads.
Although many businesses initially assumed artificial intelligence would
naturally live in the public cloud, reality is forcing a shift toward private,
on-premises systems. According to the article, this transition stems from
growing concerns about uncontrolled costs, security vulnerabilities, and
operational fit. As companies move from small experiments to organization-wide
implementation, the pay-per-token pricing models of public cloud providers
risk becoming massive utility bills that wipe out business gains.
Consequently, the future of enterprise AI leans toward a hybrid model. Rather
than relying entirely on giant public models, businesses are discovering that
smaller, specialized AI models can handle tasks better while running closely
to their own private data. This approach offers better control over
predictable workloads and eliminates surprise expenses. Furthermore, keeping
AI in-house strengthens security and data governance. Using public AI tools
raises the real danger of employees inadvertently exposing sensitive or
proprietary information. While building and managing private AI networks
requires significant investment, skill, and discipline, the long-term benefits
of controlled costs, tight security, and owned infrastructure make it a much
smarter choice for major production workloads.AI Cost, Security Pressures Push Enterprises Toward Private Cloud, Broadcom Says
According to a recent report from Broadcom, organizations are increasingly moving their artificial intelligence operations away from public cloud services and toward private cloud setups. As businesses shift from merely testing artificial intelligence to running real-world applications, they are discovering that private networks offer better handling of costs, security, and data control. The study reveals that over half of surveyed enterprises now plan to run their active intelligence systems on private infrastructure. Meanwhile, public cloud usage for these specific tasks has dropped notably over the past year. Interestingly, cost management has now surpassed security as the primary concern with public platforms, as business leaders face unpredictable pricing for computing power and data storage. Because of this, more than eighty percent of companies are either moving or considering moving their systems back in-house. While public networks remain useful for basic testing and flexible storage, the heavy demands of daily production require a more stable environment. Strict data privacy rules further encourage this transition. Ultimately, businesses are finding that dedicated internal systems provide the financial predictability and reliable protection necessary to safely grow their technological capabilities.How to Modernize Legacy Applications Without Disrupting Business
 Upgrading older software systems is a pressing challenge for modern
organizations. Delaying these updates can hinder new capabilities, consume
vital budgets with maintenance costs, and create risks as experienced
programmers retire. However, many companies hesitate because poorly planned
upgrades often cause severe business interruptions. To avoid taking systems
offline, experts recommend a gradual approach rather than attempting a risky,
sudden replacement. This method relies on careful planning and proven
structural designs. For example, organizations can build new services around
the existing system, slowly routing traffic to the new components as they are
tested and proven. Another reliable method involves running both the old and
new systems at the same time to ensure they produce identical results before
fully switching over. It is also important to use a translation layer to
prevent the flaws of the old data formats from infecting the new setup. A
successful upgrade generally follows a structured path: assessing current
dependencies, planning the target design, running a small initial pilot,
scaling the effort across other applications, and maintaining ongoing
oversight. By strictly adhering to these methods, businesses can confidently
update their technology and maintain continuous daily operations.
Upgrading older software systems is a pressing challenge for modern
organizations. Delaying these updates can hinder new capabilities, consume
vital budgets with maintenance costs, and create risks as experienced
programmers retire. However, many companies hesitate because poorly planned
upgrades often cause severe business interruptions. To avoid taking systems
offline, experts recommend a gradual approach rather than attempting a risky,
sudden replacement. This method relies on careful planning and proven
structural designs. For example, organizations can build new services around
the existing system, slowly routing traffic to the new components as they are
tested and proven. Another reliable method involves running both the old and
new systems at the same time to ensure they produce identical results before
fully switching over. It is also important to use a translation layer to
prevent the flaws of the old data formats from infecting the new setup. A
successful upgrade generally follows a structured path: assessing current
dependencies, planning the target design, running a small initial pilot,
scaling the effort across other applications, and maintaining ongoing
oversight. By strictly adhering to these methods, businesses can confidently
update their technology and maintain continuous daily operations.Data Lakehouse Architecture Layers: AI Needs More Than Just Infrastructure
 Organizations have invested heavily in data lakehouses to store and process
large amounts of information for analytics and artificial intelligence. While
these setups handle storage and compute well, they often fall short in
practical application. Data remains scattered across different cloud
environments and operational systems, meaning business teams and AI models
still struggle to access reliable information without technical assistance.
The fundamental issue is no longer about where data is kept, but how it is
connected and understood. AI tools, in particular, require more than just raw
data; they need clear context and strict governance to function accurately and
safely. To solve this, a new logical layer is emerging in data architecture.
Instead of replacing the lakehouse, this access layer sits on top of it. It
connects distributed information, applies consistent rules, and provides clear
meaning to the data without requiring it to be moved or duplicated. By pairing
traditional storage with this new governance layer, businesses create a
stronger foundation. This approach reduces friction, ensures that both human
users and systems have the context they need, and allows organizations to
focus on practical outcomes rather than managing complex infrastructure.
Organizations have invested heavily in data lakehouses to store and process
large amounts of information for analytics and artificial intelligence. While
these setups handle storage and compute well, they often fall short in
practical application. Data remains scattered across different cloud
environments and operational systems, meaning business teams and AI models
still struggle to access reliable information without technical assistance.
The fundamental issue is no longer about where data is kept, but how it is
connected and understood. AI tools, in particular, require more than just raw
data; they need clear context and strict governance to function accurately and
safely. To solve this, a new logical layer is emerging in data architecture.
Instead of replacing the lakehouse, this access layer sits on top of it. It
connects distributed information, applies consistent rules, and provides clear
meaning to the data without requiring it to be moved or duplicated. By pairing
traditional storage with this new governance layer, businesses create a
stronger foundation. This approach reduces friction, ensures that both human
users and systems have the context they need, and allows organizations to
focus on practical outcomes rather than managing complex infrastructure.The Four Elevations of Effective Fraud Prevention
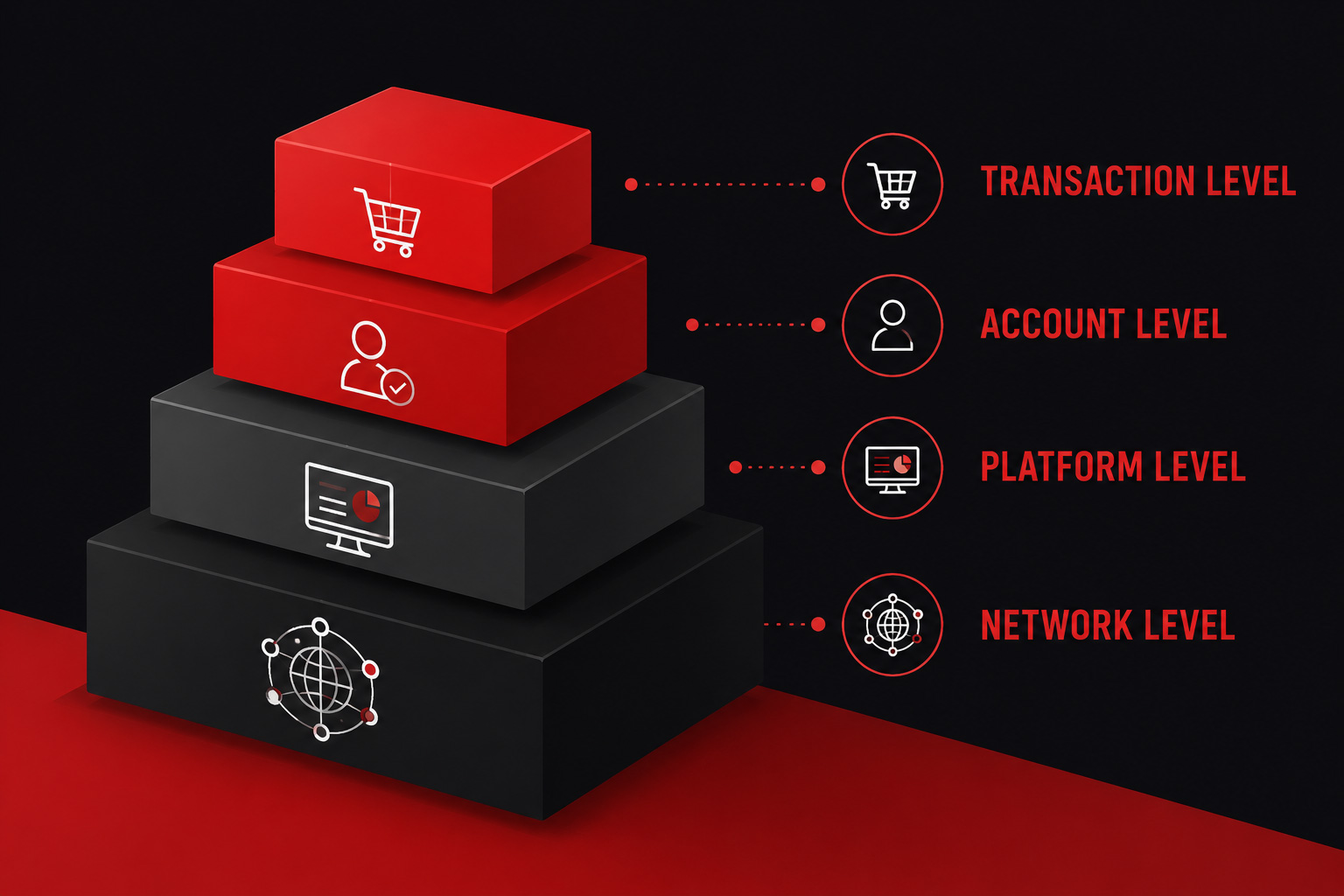 Effective fraud prevention requires more than just checking individual steps;
it demands a layered approach to monitor customer behavior comprehensively. To
build a resilient defense, organizations should evaluate activities across
four key elevations. First is the transaction level, which looks at single
interactions like logins or purchases. While important, relying on this alone
can miss larger patterns because attackers frequently change their tactics.
The second elevation is the account level, where monitoring a user's behavior
over time helps distinguish normal activity from suspicious anomalies, such as
sudden changes to contact information or unusual transfer requests. The third
elevation expands to the platform level, allowing teams to analyze trends
across all grouped accounts. This broad view helps quickly spot coordinated
attacks or fraud rings sharing the same devices or geographic locations.
Finally, the network level involves collaborating with external data providers
to share insights across different companies, ensuring that a threat detected
by one organization is immediately known to others. By integrating these four
perspectives, businesses can confidently identify complex fraud schemes early,
reduce false alarms for legitimate users, and secure their operations without
disrupting the everyday customer experience.
Effective fraud prevention requires more than just checking individual steps;
it demands a layered approach to monitor customer behavior comprehensively. To
build a resilient defense, organizations should evaluate activities across
four key elevations. First is the transaction level, which looks at single
interactions like logins or purchases. While important, relying on this alone
can miss larger patterns because attackers frequently change their tactics.
The second elevation is the account level, where monitoring a user's behavior
over time helps distinguish normal activity from suspicious anomalies, such as
sudden changes to contact information or unusual transfer requests. The third
elevation expands to the platform level, allowing teams to analyze trends
across all grouped accounts. This broad view helps quickly spot coordinated
attacks or fraud rings sharing the same devices or geographic locations.
Finally, the network level involves collaborating with external data providers
to share insights across different companies, ensuring that a threat detected
by one organization is immediately known to others. By integrating these four
perspectives, businesses can confidently identify complex fraud schemes early,
reduce false alarms for legitimate users, and secure their operations without
disrupting the everyday customer experience.
Bridging the gap between leadership's AI enthusiasm and employee pushback
 Corporate leaders and everyday employees often view artificial intelligence
through entirely different lenses. While executives and board members see AI
as a path to efficiency, cost reduction, and innovation, employees frequently
view the technology with caution. Many workers worry that AI will result in
job losses, create mentally exhausting workloads, enable invasive workplace
surveillance, and harm the environment. Chief Information Officers (CIOs) find
themselves caught in the middle and must bridge this divide. If IT leaders
ignore workforce anxieties and force AI integration, they risk damaging
company morale, losing valuable talent, and wasting money on tools that
employees simply refuse to use. To resolve this tension, CIOs need to look
beyond basic financial metrics and instead measure actual employee sentiment
and tool usage. Having open, honest conversations with staff about their fears
is essential. By creating a culture where workers feel safe sharing their
concerns, companies can build trust and ease anxiety. Rather than rolling out
technology blindly, leaders should clearly communicate the company's AI
strategy and empower early adopters to guide their peers, ensuring the
transition supports both business goals and the well-being of the team.
Corporate leaders and everyday employees often view artificial intelligence
through entirely different lenses. While executives and board members see AI
as a path to efficiency, cost reduction, and innovation, employees frequently
view the technology with caution. Many workers worry that AI will result in
job losses, create mentally exhausting workloads, enable invasive workplace
surveillance, and harm the environment. Chief Information Officers (CIOs) find
themselves caught in the middle and must bridge this divide. If IT leaders
ignore workforce anxieties and force AI integration, they risk damaging
company morale, losing valuable talent, and wasting money on tools that
employees simply refuse to use. To resolve this tension, CIOs need to look
beyond basic financial metrics and instead measure actual employee sentiment
and tool usage. Having open, honest conversations with staff about their fears
is essential. By creating a culture where workers feel safe sharing their
concerns, companies can build trust and ease anxiety. Rather than rolling out
technology blindly, leaders should clearly communicate the company's AI
strategy and empower early adopters to guide their peers, ensuring the
transition supports both business goals and the well-being of the team.
AI Works, Pull Requests Don’t: How AI Is Breaking the SDLC and What To Do About It
In the presentation "AI Works, Pull Requests Don't," Michael Webster examines
how the rise of artificial intelligence coding assistants is severely
straining traditional software development lifecycles. While AI tools
initially act as powerful amplifiers that can increase development speed by
three to five times, this burst in productivity is often temporary. Developers
and AI agents are generating massive amounts of code, sometimes adding
twenty-five times more code than they delete. As a result, human reviewers are
overwhelmed by enormous pull requests, creating significant bottlenecks in the
review process and leading to a steady accumulation of technical debt. Drawing
on queuing theory, Webster explains that delays inevitably occur when the rate
of incoming code surpasses the team's capacity to process and review it. To
resolve these challenges, engineering teams must adapt their validation
pipelines. He recommends implementing test impact analysis, a method that runs
only the tests affected by recent code changes rather than the entire test
suite. By relying on automated validation tools to quickly verify AI-generated
output, teams can successfully maintain software stability, reduce testing
costs, and manage the high volume of code without sacrificing overall
quality.
Hackers Exploit Weak Credentials and Internet-Facing PLCs to Breach Water Utilities
Water and wastewater utilities across the United States and Europe are facing
increasing threats from state-sponsored groups affiliated with Iran, Russia,
and China. Rather than relying on complex software, these attackers exploit
fundamental security oversights, like internet-exposed control systems,
default passwords, and inadequate network separation. This shift indicates
that targeting civilian infrastructure has become a deliberate method to test
emergency responses, create public anxiety, and position adversaries for
future conflicts. For instance, Iranian-linked groups have used factory
credentials to access unprotected systems, while Russian-affiliated actors
actively disrupted operations by overflowing water tanks in Texas and opening
floodgates in Norway. Meanwhile, Chinese groups take a quieter approach,
establishing long-term access within utility networks to maintain leverage for
potential disputes. To counter these vulnerabilities, security experts advise
facility operators to implement basic defenses immediately. These include
removing physical control systems from direct internet exposure, enforcing
strict login requirements, replacing default passwords, and firmly separating
industrial equipment from standard computer networks. By addressing these
entry points, utilities can effectively reduce their risk of compromise and
safely protect vital public water resources from further interference.




























