Quote for the day:
“Success does not consist in never making mistakes but in never making the same one a second time.” --George Bernard Shaw
Google Adds Quantum-Resistant Digital Signatures to Cloud KMS
_Science_Photo_Library_Alamy.jpg?width=1280&auto=webp&quality=95&format=jpg&disable=upscale) After a process that kicked off nearly a decade ago, NIST officially published
the first three PQC standards last August. The standards, based on advanced
encryption algorithms, are now known as FIPS 203, FIPS 204, and FIPS 205,
although additional specifications are still under review by NIST. Google's
strategy calls for support for the current and future NIST standards. While
Cloud KMS will eventually support all three NIST standards, Google's initial
release implements the two digital signature algorithms: FIPS 204, which enables
lattice-based digital signatures, and FIPS 205, which is for stateless
hash-based digital signatures. Porter says support for FIPS 203, which is for
asymmetric cryptography, will come later in the year. ... "Making the open
source libraries and Cloud KMS to support those specific signatures with those
keys will give the opportunity for our customers to validate those performance
implications to their environments when they use those keys for the signing of
longer linked environments," Porter explains. Google is not the only major
player adding open source libraries that support the NIST standards. In
September, Microsoft started releasing support for the NIST standards in
SymCrypt, its open source core cryptographic library main cryptographic library
used in Azure, Microsoft 365, Windows 11, Windows 10, Windows Server, Azure
Stack HCI, and Azure Linux.
After a process that kicked off nearly a decade ago, NIST officially published
the first three PQC standards last August. The standards, based on advanced
encryption algorithms, are now known as FIPS 203, FIPS 204, and FIPS 205,
although additional specifications are still under review by NIST. Google's
strategy calls for support for the current and future NIST standards. While
Cloud KMS will eventually support all three NIST standards, Google's initial
release implements the two digital signature algorithms: FIPS 204, which enables
lattice-based digital signatures, and FIPS 205, which is for stateless
hash-based digital signatures. Porter says support for FIPS 203, which is for
asymmetric cryptography, will come later in the year. ... "Making the open
source libraries and Cloud KMS to support those specific signatures with those
keys will give the opportunity for our customers to validate those performance
implications to their environments when they use those keys for the signing of
longer linked environments," Porter explains. Google is not the only major
player adding open source libraries that support the NIST standards. In
September, Microsoft started releasing support for the NIST standards in
SymCrypt, its open source core cryptographic library main cryptographic library
used in Azure, Microsoft 365, Windows 11, Windows 10, Windows Server, Azure
Stack HCI, and Azure Linux. The most critical job skill you need to thrive in the AI revolution
 A few weeks ago, The World Economic Forum dropped its predictions for the
future of jobs and the seismic shift in the workforce over the next five years
(2030). ... Half of the employers plan to reorient business strategies in
response to the rise of AI. In fact, 2 in 3 plan to hire for AI-specific
skills (this is where the new jobs will come from). 40% of those same
businesses also think their workforce will shrink due to AI automating tasks.
On the surface, this might seem like doom and gloom, but remember, we are
talking about 78 million new jobs by 2030. It is safe to assume some of that
workforce will find employment in companies that don't exist yet. Another
insight that stood out to me but deserves its own article is that an aging
population will drive the demand for more healthcare jobs. This could be a
huge opportunity. Let me know in the comments if you want me to discuss the
possibilities. ... As for your big opportunity, I feel like everyone is so
focused on the shiny objects, like what are the best prompts or the best tool?
Those are fine, but not enough focus is placed on the soft skills. It's as if
we're forgetting that even though we use AI to create, our creations are still
intended for humans. If I had to say it another way, it is almost like some
businesses are using AI and becoming sloppy. Not caring about the customer,
and so on.
A few weeks ago, The World Economic Forum dropped its predictions for the
future of jobs and the seismic shift in the workforce over the next five years
(2030). ... Half of the employers plan to reorient business strategies in
response to the rise of AI. In fact, 2 in 3 plan to hire for AI-specific
skills (this is where the new jobs will come from). 40% of those same
businesses also think their workforce will shrink due to AI automating tasks.
On the surface, this might seem like doom and gloom, but remember, we are
talking about 78 million new jobs by 2030. It is safe to assume some of that
workforce will find employment in companies that don't exist yet. Another
insight that stood out to me but deserves its own article is that an aging
population will drive the demand for more healthcare jobs. This could be a
huge opportunity. Let me know in the comments if you want me to discuss the
possibilities. ... As for your big opportunity, I feel like everyone is so
focused on the shiny objects, like what are the best prompts or the best tool?
Those are fine, but not enough focus is placed on the soft skills. It's as if
we're forgetting that even though we use AI to create, our creations are still
intended for humans. If I had to say it another way, it is almost like some
businesses are using AI and becoming sloppy. Not caring about the customer,
and so on.MDR, EDR Markets See Wave of M&A as Competition Intensifies
 Organizations traditionally relied on managed security services for log
monitoring and basic alerting. MDR took this a step further by offering
real-time threat detection, investigation and response. At the same time,
vendors came to realize that endpoint visibility alone through EDR was
insufficient, leading to XDR, which integrates signals from multiple layers,
including cloud, network and identity systems. "It's complicated to learn the
skills to be able to operate these kinds of platforms really efficiently, and
it's even more challenging to be able to do it 24/7/365," Levy said. "Most
organizations simply aren't equipped to be able to run a global SOC with
multiple shifts." While XDR expanded detection capabilities, Levy said it also
introduced operational complexities, with most companies lacking the expertise
and resources to manage a sophisticated security platform 24/7, leading to the
rise of MDR as a fully managed security service. True MDR should go beyond the
endpoint and include threat detection across cloud environments, networks and
identity systems, Schneider said. "Once partners get engaged and really see
the value in managed EDR, the conversation immediately goes to, 'Can you do
the same thing for my firewalls? Can you do the same thing for my NDR
solution? Can you do the same thing for my identity solution?'"
Organizations traditionally relied on managed security services for log
monitoring and basic alerting. MDR took this a step further by offering
real-time threat detection, investigation and response. At the same time,
vendors came to realize that endpoint visibility alone through EDR was
insufficient, leading to XDR, which integrates signals from multiple layers,
including cloud, network and identity systems. "It's complicated to learn the
skills to be able to operate these kinds of platforms really efficiently, and
it's even more challenging to be able to do it 24/7/365," Levy said. "Most
organizations simply aren't equipped to be able to run a global SOC with
multiple shifts." While XDR expanded detection capabilities, Levy said it also
introduced operational complexities, with most companies lacking the expertise
and resources to manage a sophisticated security platform 24/7, leading to the
rise of MDR as a fully managed security service. True MDR should go beyond the
endpoint and include threat detection across cloud environments, networks and
identity systems, Schneider said. "Once partners get engaged and really see
the value in managed EDR, the conversation immediately goes to, 'Can you do
the same thing for my firewalls? Can you do the same thing for my NDR
solution? Can you do the same thing for my identity solution?'" We need to talk about the F word (‘friction’ in enterprise, that is)
Struggling to Become Truly Data-Driven? Focus on Access and Culture, Not Tech
 Success in data strategy requires strong leadership commitment and cultural
transformation. The playbook emphasizes the role of leaders in advancing data
literacy and encouraging data-driven decision-making. This includes
identifying and empowering "data champions" across the organization and
creating communities of practice to share knowledge and best practices.
Training and development play crucial roles in building data capabilities. The
report recommends targeted training programs for employees central to data
usage, utilizing both online and in-person resources. Investment in training
yields significant returns through improved efficiency, better
decision-making, and enhanced customer service. However, training should not
be a one-size-fits-all approach; it should be tailored to different roles and
skill levels within the organization. The report emphasizes that becoming a
data-driven organization is an ongoing journey rather than a destination.
Financial institutions must continuously evolve their data strategies to keep
pace with changing technology and customer expectations. This includes
exploring emerging technologies like artificial intelligence and machine
learning, while ensuring they maintain a strong foundation in data quality and
governance.
Success in data strategy requires strong leadership commitment and cultural
transformation. The playbook emphasizes the role of leaders in advancing data
literacy and encouraging data-driven decision-making. This includes
identifying and empowering "data champions" across the organization and
creating communities of practice to share knowledge and best practices.
Training and development play crucial roles in building data capabilities. The
report recommends targeted training programs for employees central to data
usage, utilizing both online and in-person resources. Investment in training
yields significant returns through improved efficiency, better
decision-making, and enhanced customer service. However, training should not
be a one-size-fits-all approach; it should be tailored to different roles and
skill levels within the organization. The report emphasizes that becoming a
data-driven organization is an ongoing journey rather than a destination.
Financial institutions must continuously evolve their data strategies to keep
pace with changing technology and customer expectations. This includes
exploring emerging technologies like artificial intelligence and machine
learning, while ensuring they maintain a strong foundation in data quality and
governance.Introduction to Service Mesh
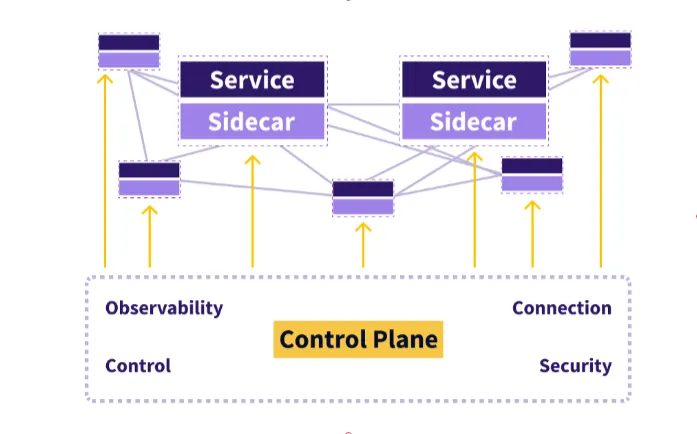
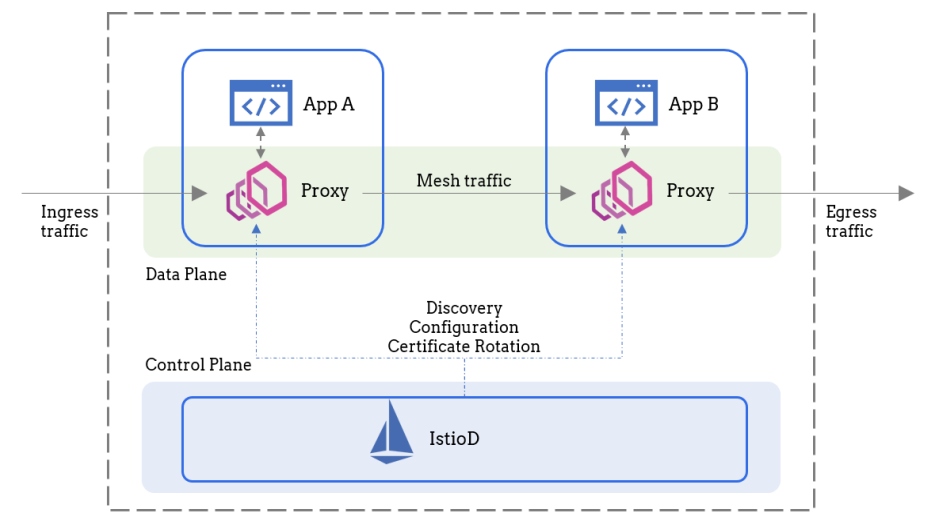
 A service mesh acts as a layer encompassing services running within a
distributed application that facilitates dependable and visible communication
among microservices. It oversees how services interact with one another,
handling tasks such as discovering services, distributing workloads evenly,
recovering from failures, collecting metrics and monitoring performance. ...
By separating network management duties from the application code, a service
mesh makes it easier for developers and operations teams to handle tasks
efficiently. Developers can concentrate on creating business logic without the
need to deal with integrating service discovery, load balancing or security
protocols into their applications. Operations teams can take advantage of the
management of policies and configurations provided by the service mesh’s
control plane. ... When selecting a service mesh, it’s important to consider
scalability. Make sure that the service mesh is capable of accommodating the
size of your microservices setup and can adapt as your application grows.
Assess how the service mesh affects your system’s performance and the load
added by sidecar proxies. A scalable service mesh should deliver performance
and minimal delays when adding more services and incurring higher traffic
levels.
A service mesh acts as a layer encompassing services running within a
distributed application that facilitates dependable and visible communication
among microservices. It oversees how services interact with one another,
handling tasks such as discovering services, distributing workloads evenly,
recovering from failures, collecting metrics and monitoring performance. ...
By separating network management duties from the application code, a service
mesh makes it easier for developers and operations teams to handle tasks
efficiently. Developers can concentrate on creating business logic without the
need to deal with integrating service discovery, load balancing or security
protocols into their applications. Operations teams can take advantage of the
management of policies and configurations provided by the service mesh’s
control plane. ... When selecting a service mesh, it’s important to consider
scalability. Make sure that the service mesh is capable of accommodating the
size of your microservices setup and can adapt as your application grows.
Assess how the service mesh affects your system’s performance and the load
added by sidecar proxies. A scalable service mesh should deliver performance
and minimal delays when adding more services and incurring higher traffic
levels.Why enterprises fail at finops
 One of the most significant challenges is the lack of integration between the
finops and engineering teams responsible for building and deploying cloud
applications. McKinsey’s report showed that many organizations struggle to
capture savings beyond the immediate finops team’s mandate because these teams
often lack the incentives or access to cloud cost data. Consequently, many
well-meaning optimization efforts fall by the wayside as engineers juggle
multiple priorities or lack the resources to focus on cost-related
improvements. Another issue is the lack of systematic implementation of finops
best practices. This is where FaC becomes essential by incorporating finops
processes directly into application configurations to make them foolproof. FaC
can dramatically reduce costs by integrating financial management principles
directly into the infrastructure management life cycle. Organizations can
enforce budget constraints by automatically identifying opportunities for cost
reduction, supporting more efficient resource scheduling, and employing
cloud-native services to decrease operational cloud resource expenses. Many
organizations struggle with basic cloud hygiene practices. They’re not
effectively identifying and eliminating obvious sources of waste, such as
underutilized resources, oversized virtual machines, and redundant storage
volumes.
One of the most significant challenges is the lack of integration between the
finops and engineering teams responsible for building and deploying cloud
applications. McKinsey’s report showed that many organizations struggle to
capture savings beyond the immediate finops team’s mandate because these teams
often lack the incentives or access to cloud cost data. Consequently, many
well-meaning optimization efforts fall by the wayside as engineers juggle
multiple priorities or lack the resources to focus on cost-related
improvements. Another issue is the lack of systematic implementation of finops
best practices. This is where FaC becomes essential by incorporating finops
processes directly into application configurations to make them foolproof. FaC
can dramatically reduce costs by integrating financial management principles
directly into the infrastructure management life cycle. Organizations can
enforce budget constraints by automatically identifying opportunities for cost
reduction, supporting more efficient resource scheduling, and employing
cloud-native services to decrease operational cloud resource expenses. Many
organizations struggle with basic cloud hygiene practices. They’re not
effectively identifying and eliminating obvious sources of waste, such as
underutilized resources, oversized virtual machines, and redundant storage
volumes.
Building the next-gen creator economy with AI agents
 Autonomous agents simplify content distribution and monetization by automating
tasks such as pricing, licensing, and revenue sharing, freeing creators to
focus on their craft. For instance, these agents can optimize pricing
strategies based on market demand or manage revenue splits transparently.
Unlike traditional AI tools, decentralized agents can operate trustlessly
onchain, ensuring transparency, reducing costs, and eliminating third-party
intermediaries. By leveraging programmable rules and onchain verification,
autonomous agents also allow creators to explore new revenue streams—such as
micro-licensing or fractional ownership of digital assets—giving them control
over their intellectual property while tapping into innovative monetization
models. Ethical concerns, such as licensing and copyright issues, can be
addressed through programmable licensing rights embedded in content metadata.
... The use of trustless, onchain computation means that creators are not
reliant on centralized APIs or platforms, which could compromise their data or
artistic vision. Unlike many current AI agents that depend on centralized APIs
like OpenAI, these decentralized agents operate sustainably and transparently,
avoiding vulnerabilities tied to centralized control.
Autonomous agents simplify content distribution and monetization by automating
tasks such as pricing, licensing, and revenue sharing, freeing creators to
focus on their craft. For instance, these agents can optimize pricing
strategies based on market demand or manage revenue splits transparently.
Unlike traditional AI tools, decentralized agents can operate trustlessly
onchain, ensuring transparency, reducing costs, and eliminating third-party
intermediaries. By leveraging programmable rules and onchain verification,
autonomous agents also allow creators to explore new revenue streams—such as
micro-licensing or fractional ownership of digital assets—giving them control
over their intellectual property while tapping into innovative monetization
models. Ethical concerns, such as licensing and copyright issues, can be
addressed through programmable licensing rights embedded in content metadata.
... The use of trustless, onchain computation means that creators are not
reliant on centralized APIs or platforms, which could compromise their data or
artistic vision. Unlike many current AI agents that depend on centralized APIs
like OpenAI, these decentralized agents operate sustainably and transparently,
avoiding vulnerabilities tied to centralized control. The Future of Cybersecurity: AI-Driven Threat Detection and Prevention
 Artificial intelligence has revolutionized the way organizations respond to
threat detection. Contemporary AI systems are capable of examining huge
volumes of network traffic, log data, and user activity in real-time,
detecting subtle patterns that could represent a security compromise.
AI-powered Security Information and Event Management (SIEM) solutions can
examine billions of security events per day, correlating seemingly unrelated
activity to reveal advanced attack campaigns. ... Machine learning algorithms
are now shifting from reactive security to predictive threat prevention. By
examining past patterns of attacks and present system activity, AI can detect
potential security threats before they become real threats. This is especially
effective in insider threat detection, where AI algorithms can detect slight
variations in employee behavior that could be a sign of compromise or
malicious activity. ... When an incident is detected, AI-based security
orchestration platforms can respond automatically, cutting in half the lag
time between detection and mitigation. They can isolate infected systems,
withdraw misused credentials, and apply countermeasures in seconds –
operations that it would take human teams hours or even days to do manually.
Artificial intelligence has revolutionized the way organizations respond to
threat detection. Contemporary AI systems are capable of examining huge
volumes of network traffic, log data, and user activity in real-time,
detecting subtle patterns that could represent a security compromise.
AI-powered Security Information and Event Management (SIEM) solutions can
examine billions of security events per day, correlating seemingly unrelated
activity to reveal advanced attack campaigns. ... Machine learning algorithms
are now shifting from reactive security to predictive threat prevention. By
examining past patterns of attacks and present system activity, AI can detect
potential security threats before they become real threats. This is especially
effective in insider threat detection, where AI algorithms can detect slight
variations in employee behavior that could be a sign of compromise or
malicious activity. ... When an incident is detected, AI-based security
orchestration platforms can respond automatically, cutting in half the lag
time between detection and mitigation. They can isolate infected systems,
withdraw misused credentials, and apply countermeasures in seconds –
operations that it would take human teams hours or even days to do manually.