What are Governance Tokens? How Token Owners Shape a DAO's Direction

Governance tokens represent ownership in a decentralized protocol. They provide
token holders with certain rights that influence a protocol’s direction. This
could include which new products or features to develop, how to spend a budget,
which integrations or partnerships should be pursued, and more. Generally
speaking, exercising this influence can take two forms. First, governance token
holders can propose changes through a formal proposal submission process. If
certain criteria are met and the proposal goes to a vote, governance token
holders can use their tokens to vote on the proposed changes. The specific
mechanisms and processes through which these rights are exercised differ across
protocols. ... In traditional corporations, a concentrated executive
body—typically some combination of a C-Suite, board of directors, and
shareholders—has sole discretion over decisions pertaining to the organization’s
strategic direction. DAOs differ from traditional corporations in that they
don’t have a centralized group of decision-makers; but they still need to make
decisions that influence the organization’s future.
Remote work vs office life: Lots of experiments and no easy answers
"It's important that it's an iterative process because we're going to find out
things that we didn't necessarily expect in our assumptions around how the
styles of work that we will be carrying out may well change as we start to reach
a balance," he says. Lloyds is examining the work that takes place in offices,
branches and homes, and is thinking about how the bank will connect people
across these spaces in what Kegode refers to as "a mindful way". Developing that
understanding involves constant conversations and an analysis of the crossover
between business demands, individual needs and team requirements. "It's always
about looking at how we can use technology as an enabler to make us more human,"
he says. "How can we use technology to enhance our human traits and the things
that make us unique that machines can't do?" Lloyds started introducing
Microsoft Teams just before the pandemic, which served the bank well when
lockdown began. While video-conferencing tech has kept workers productive during
the past two years, the future of the workplace will require careful
conversations about how tools are adopted and adapted.
PCI SSC Releases Data Security Standard Version 4.0
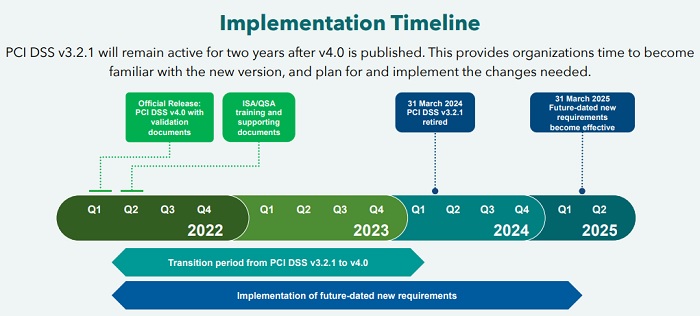
The PCI Security Standards Council on Thursday released the Payment Card
Industry Data Security Standard version 4.0. The Council says that the latest
version's improvements are intended to counter evolving threats and
technologies, and the new version will enable innovative methods to combat new
threats. Organizations currently use PCI DSS version 3.2.1. The council is
allowing two years - until March 31, 2024 - for the industry to conduct training
and provide education regarding implementation of the changes and updates in
version 4.0. While the new standard will be considered best practice, the
current version of PCI DSS will remain active during this time. After March 31,
2024, it will be retired over the next year, and the new requirements will
become effective after March 31, 2025. The global payments industry received
feedback on the latest changes over the course of three years, during which more
than 200 organizations provided more than 6,000 suggestions to ensure the
standard continues to meet the ever-changing landscape of payment security, the
council says.
Building Trust with Responsible AI

User-centered reliable AI systems should be created using basic best practices
for software systems and methods that address machine learning-specific
problems. The following points should be kept in mind while designing a
reliable and responsible AI. Consider augmenting and assisting users with a
variety of options. One should use a human-centered design approach. This
includes building a model with appropriate disclosures, clarity, and control
for the users. Engage a wide range of users and use-case scenarios, and
incorporate comments before and during the project’s development; Rather
than using a single metric, you should use a combination to understand better
the tradeoffs between different types of errors and experiences. Make sure
your metrics are appropriate for the context and purpose of your system; for
example, a fire alarm system should have a high recall, even if it implies a
false alarm now and then; ML models will reflect the data they are
trained on, so make sure you understand your raw data. If this isn’t possible,
such as with sensitive raw data, try to comprehend your input data as much as
possible while still maintaining privacy; Understand the limitations of
your dataset and communicate them with the users whenever possible.
The CISO as brand enabler, customer advocate, and product visionary

Quantifying the value of a corporate brand is tough. But it’s clear that your
organization’s brand is as much an asset as the devices and networks that the
CISO is charged with protecting – in fact, the brand may be your
organization’s largest single asset. A recent Forbes/MASB report states that
brand assets drive approximately 20% of enterprise value on average. Doesn’t
that sound like something worth protecting? Yes, the creation and growth of
the brand is typically the responsibility of the marketing organization and
the CMO (chief marketing officer). But it’s not unusual for marketing to feel
like it’s outracing the other business functions, including the CISO, and they
are anxious for everyone to “catch up” and join them. The CISO can act as a
useful counterweight to help marketing achieve its goals safely, in good times
and bad. For example, isn’t it important to fully coordinate a breach response
between these two groups in a way that best preserves the value of your brand?
Those brands that emerge out of a high-profile information security incident
stronger don’t get there by accident.
Introducing the MeshaVerse: Next-Gen Data Mesh 2.0
When designing MeshaVerse, our primary focus was on preserving
decentralization while ensuring data reliability, data quality, and scale. Our
novel approach includes implementing Dymlink, a symlink in the data lakehouse,
and a new SlinkSync (Symbolic link Sync), a symlink that links Dymlinks
together – similar to a linked list. By establishing which symlinks can be
composed as a set – using either a direct probable or indirect inverse
probable match – we are able to infer the convergence criteria of a
nondivergent series (i.e the compressed representation of the data) while
always ensuring we stay within the gradient of the curve. As a result, we’re
able to prevent an infinite recursion that can potentially stale all data
retrieval from the Data Mesh. Stay tuned for a future blog, where we’ll dive
deeper into this approach. The integrity of this virtual data is ensured in
real-time and at scale using a more recent implementation of Databricks
Brickchain, taking advantage of all global compute power and therefore
offering the potential to store the entire planet’s data with a fraction of
the footprint.
DAOs could revolutionize how startups are run

Blockchain technology has ushered in the creation of businesses that allow
users greater control over the services they choose to use. These emerging
services turn the top-down approach of traditional tech firms on its head,
allowing patrons to have a say in the development of a new generation of
Web3-based games, apps, and companies. VCs currently have a monopoly on
decision-making in their chosen investments, giving them the power to dictate
critical judgments and the direction of these companies. While this sounds
fair in theory — given the money they provide — this can also mean that
critical decisions get slowed, or the original vision for the company diverges
entirely. However, under the Web3 model, it makes sense that key business
decisions should be as decentralized as the infrastructure that underpins
them. Decentralized voting via a token governance structure means that anyone
— regardless of their ethnicity, creed or financial status — can get involved
and benefit from being part of a like-minded community of peers, removed from
the hierarchical structure of the standard business model.
5 things CIOs should know about cloud service providers

While cloud service providers may offer similar capabilities, they are not
actually the same. Determining the best one for your unique requirements and
goals is another critical piece of your strategy. “When working with cloud
service providers, it’s important to align the platform with the company’s
unique business objectives,” says Scott Gordon, enterprise architect director,
cloud infrastructure services at Capgemini Americas. “Every organization has
its own situation, and the cloud strategy must be catered to solve those
customized business challenges to create value and results.” While there might
be some plain-vanilla workloads where the choice of cloud service provider
might not have overwhelming implications, most organizational realities are
more complex. Thinking back to the advice from Haff and LaCour, this is again
where specific motivations or goals have a big impact. Gordon notes, for
example, the importance of evaluating the end-to-end life cycles of your
on-premises applications and determining which ones will require modernization
and/or migration at some point.
General Catalyst’s Clark Talks Opportunistic Investing in Tech

We have to balance thematic with what we refer to as opportunistic work. We have
to pay attention and engage with companies that get referred to us through our
founders and other parts of our network. There are other incubator
functions--that is important for us to engage in because we don’t necessarily
see everything as we view things thematically. It’s just impossible. We do some
of our very best work when we are being more intentional. ... Another area is
dynamic workforce, which is a little fuzzy. I fit things like Remote.com,
Awardco, and Hopin into these things, as well as things like Loom and Glean
where it’s not just the tools end users are using because they are much more
project-based than they used to be. Now it’s like, “You’re going to do this
project and when that’s done, there’s another one. Maybe you do two at once and
the teams you work with are different.” It’s a different system that we’ve put
in place. Distributed work is permanent now. We will get back in the office one,
two, three days a week -- or not.
Improving open source software governance stature
The first line of defense against vulnerable open source libraries is to scan a
project's dependencies for libraries known to have security vulnerabilities.
OWASP Dependency-Check is a tool that returns a report that identifies
vulnerable dependencies, along with their common vulnerabilities and exposures
(CVEs). There are different ways to run OWASP Dependency-Check, such as via a
command-line interface, an Apache Maven plugin, an Ant task or a Jenkins plugin,
which enables easy integration into any CI/CD pipeline. Using a tool that
creates actionable reports is only as useful as the process enforced around the
tool. Run OWASP Dependency-Check on a consistent schedule to scan the codebase
against the latest updates of newly discovered CVEs. Dedicate time and plan for
identified CVEs. When using open source dependencies, consider the licenses that
govern their use. Licenses for open source projects define how to use, copy and
distribute the software. Depending on the application's software and
distribution types, the application's source code might not permit certain open
source tools.
Quote for the day:
"Brilliant strategy is the best route
to desirable ends with available means." -- Max McKeown











:format(webp)/cdn.vox-cdn.com/uploads/chorus_image/image/70691632/acastro_180604_1777_apple_wwdc_0003.0.jpg)
























